
Groq,LPU到底是甚麼?為甚麼Nvidia必須買下 Groq的靈魂?- 深度分析第27期:Nvidia「收購」Groq


2024 年 2 月 19 日。
對於大多數人來說,這只是一個普通的星期一。但對Groq這家公司來說,卻是非常重要的一天。
一位名叫 Matt Shumer 的用戶上傳了一段僅有 3秒的錄屏影片。沒有花哨的剪輯,沒有激昂的配樂,只有一個簡單的對話框。
他在框內輸入了一個複雜的問題。
在 ChatGPT 建立的「常識」裡,用戶習慣了等待。你會看到游標閃爍,然後文字像老式打字機一樣,一個字、一個字地蹦出來。你習慣了在 AI「思考」時去喝口水。
但在 Shumer 的影片中,事情發生得太快,以至於大腦幾乎來不及處理。
就在他按下 Enter 鍵的瞬間,數百個單詞組成的完美答案,包含引用來源和結構化建議,在不到一秒鐘的時間內瞬間刷滿螢幕。
沒有打字機效果,沒有等待,文字出現的速度快到肉眼無法捕捉。
這條推文像野火一樣蔓延。在那一刻,世界突然意識到:
我們過去兩年所經歷的AI延遲,並不是物理定律的限制,而是硬體的限制。
當大語言模型在 Groq 的晶片上跑起來時,人們第一次感覺到了那種電影裡才有的、與機器無縫對話的未來。
Groq,這家名字聽起來和Elon Musk 的 Grok 僅一字之差的公司,在一夜之間從「默默無聞的晶片新創」變成了「Nvidia的挑戰者」。
時間快轉到 2025 年 12 月 24 日,聖誕夜前夕。
沒有慶功宴,沒有上市敲鐘的歡呼。一則重磅新聞悄然登上了財經版頭條:
Nvidia宣布以 200 億美元的價格「收購」Groq 的核心資產與人才。
第一章:TPU 之父的叛逆

在矽谷,Jonathan Ross 這個名字通常與一個縮寫詞連在一起:TPU(Tensor Processing Unit,張量處理單元)。
2013 年的 Google 正面臨一場看不見的危機。
隨著語音識別、圖像分類等 AI 功能的普及,Google 的數據中心正面臨被算力需求壓垮的風險。
內部的工程師算了一筆帳:如果讓每一位安卓用戶每天只使用 3 分鐘的語音識別,Google 就需要將現有的數據中心數量翻倍。這意味著數百億美元的額外支出,這在商業上是不可持續的。
當時的解決方案通常是購買更多的 CPU,或者開始嘗試使用Nvidia的 GPU。但 Jonathan Ross,這位當時還在 Google 廣告部門工作的軟體工程師,有了一個瘋狂的想法。
利用 Google 著名的「20% 自由時間」政策——這項政策曾誕生了 Gmail 和 AdSense——Ross 開始了一個代號隱秘的硬體專案。
他的想法很簡單,卻極具顛覆性:
為什麼我們要在為圖形渲染設計的晶片(GPU)上跑 AI?為什麼不從零開始,設計一顆專門為神經網路數學運算而生的晶片?
這就是 TPU 的雛形。
Ross 不僅僅是提出想法,他親手設計並領導了這個專案。在短短 15 個月內——這在硬體開發史上簡直是神速——他和團隊完成了從設計、驗證到部署的全過程。
當第一代 TPU 插上 Google 的伺服器時,效果是震撼的。它的每瓦運算性能(TOPS/Watt)表現驚人——是當時 GPU 的 29 倍,更是傳統 CPU 的 83 倍。
它拯救了 Google 的運算危機,隨後更是成為了 AlphaGo 擊敗李世石背後的秘密武器。Ross 一戰成名,成為了 Google 內部的傳奇人物,他的發明支撐起了 Google Search、Photos 和 YouTube 幾乎核心命脈的算力。
按理說,Ross 應該在 Google 享受著頂級工程師的榮耀,不斷在組織中升職加薪。但在 2016 年,他卻做了一個讓所有人驚訝的決定:辭職。

為什麼?
因為 Ross 看到了 TPU 的侷限性——不是技術上的,而是哲學上的。
TPU 是強大的,但它被鎖在 Google 的高牆之內,它是一個「封閉的武器」。只有 Google 的工程師,或者購買 Google Cloud 昂貴服務的企業才能使用它。
對於外部世界——那些大學實驗室的學生、車庫裡的創業者、不想被 Google 生態綁架的開發者——TPU 就像是一個遙不可及的神話。
Ross 的野心遠不止於此。他在 Google X(Google 的秘密實驗室)工作期間,深刻地意識到:AI 的未來不應該被少數幾家巨頭壟斷。
「如果算力是新時代的石油,那麼鑽井平台不應該只屬於 Google。」
Ross 在後來的一次採訪中暗示過這種想法。
他看到了一個巨大的市場空白:世界需要一種比 GPU 更快、比 TPU 更開放的晶片。
他想要「民主化」這種超級算力。
2016 年,Ross 帶著一部份他原來團隊的頂級晶片工程師出走,創立了 Groq。
這個名字取自科幻大師海因萊因的小說《異鄉異客》(Stranger in a Strange Land)中的詞彙 “Grok”,意為「深刻地、直覺地理解」。
這也隱喻了 Ross 的技術哲學:他要設計一種能讓機器「瞬間理解」人類語言的晶片。
第二章:離經叛道的 LPU

2016 年,當 Jonathan Ross 離開 Google 創立 Groq 時,他給自己的新發明取了一個看似狂妄的名字:LPU (Language Processing Unit,語言處理單元)。
在當時,這簡直是行銷上的自殺。那一年,AI 的主流戰場是圖像識別(ImageNet),而不是語言。
大語言模型(LLM)的概念還處於嬰兒期,將晶片命名為「語言處理單元」,就像在汽車剛發明時,宣稱自己造了一架「飛機」一樣,既超前又令人困惑。
但 Ross 並不在乎。他看到的未來與當時的矽谷截然不同。他認為,現有的晶片架構——包括 CPU 和 GPU——都存在一個根本性的基因缺陷。
為了理解 Groq 為什麼被視為「離經叛道」,我們必須先理解它的對手:Nvidia的 GPU。
繁忙的十字路口 vs. 精密的瑞士鐘錶
. Introduction | by Harisudhan.S | Medium")
Nvidia的 GPU 本質上是一個機率性(Probabilistic)的機器。
想像一下,GPU 的內部就像是一個擁有數千條車道的超級繁忙十字路口。數據包就像是一輛輛汽車,它們在記憶體和計算核心之間穿梭。
為了管理這些巨大的車流,GPU 需要大量的「交通警察」——也就是硬體調度器(Schedulers)、緩存控制器(Cache Controllers)和分支預測器。
這些「警察」的工作是動態指揮交通:「你先停下,讓那輛車先過」、「現在記憶體堵塞了,大家等一等」。
這就導致了一個問題:不可預測性。
你永遠不知道一輛車通過十字路口確切需要多少毫秒。有時是 5 毫秒,有時因為堵車變成了 10 毫秒。這就是為什麼你在玩遊戲或使用 ChatGPT 時,偶爾會感覺到卡頓或延遲的波動。
Jonathan Ross 厭惡這種混亂。
Groq 的 LPU 採用了一種完全相反的哲學:確定性(Determinism)。
在 LPU 的世界裡,沒有交通警察,也沒有紅綠燈。所有的數據流動,在晶片開始運作之前,就已經被軟體編譯器(Compiler)精確地安排好了。
這就像是一隻機械結構精密的瑞士鐘錶,或者是工廠裡的自動化流水線。編譯器知道每一個電子在每一納秒(Nanosecond)的確切位置。數據在晶片上的流動是完全同步的,就像軍隊閱兵一樣整齊劃一。
因為不需要「交通警察」,Groq 砍掉了晶片上大量用於調度和緩存控制的電路。這帶來了兩個巨大的優勢:
極致的效率: 更多的晶片面積被用於實際的計算,而不是管理計算。
零延遲抖動: LPU 的反應時間是恆定的。這對於需要即時反應的系統(如自動駕駛或即時語音翻譯)來說,是至關重要的特性。
SRAM 的豪賭:法拉利與貨車的抉擇
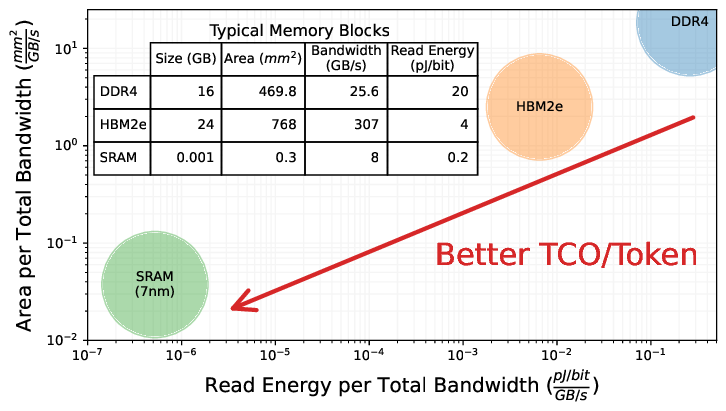
除了「確定性」,Groq 還做了一個在當時看來極其冒險的硬體決策:拋棄 HBM(高頻寬記憶體),全押 SRAM(靜態隨機存取記憶體)。
這是一個關於「容量」與「速度」的終極取捨。
Nvidia的選擇 (HBM): 這就像是一輛巨大的貨車。它能裝載海量的貨物(數據),一次可以運送 80GB 甚至更多的模型權重。但它的缺點是,貨車裝卸貨很慢,而且倉庫(記憶體)離工廠(計算核心)有一段距離,數據傳輸存在物理瓶頸。
Groq 的選擇 (SRAM): 這就像是一輛法拉利跑車。它的後備箱非常小(單個晶片只有 230MB 容量),裝不了多少東西。但它的速度快得驚人。Groq 將 SRAM 直接鋪在計算核心旁邊,數據傳輸速度達到了驚人的 80TB/s——這是Nvidia HBM 速度的 10 倍以上。
這就是 LPU 速度神話的物理基礎。在 LPU 上,數據不需要在倉庫和工廠之間來回奔波,它就在手邊。
然而,這也是 Groq 早期最大的軟肋。
因為 SRAM 非常昂貴且佔空間,單顆 LPU 無法裝下任何現代的大型 AI 模型。要運行一個大模型,你需要將數百顆 LPU 連接在一起,讓它們像一個巨型大腦一樣協同工作。
在 2016 年到 2022 年間,這被視為一種極其不經濟的架構。
「為什麼我要買 500 顆晶片來跑一個模型,而Nvidia的一顆晶片就能裝下?」這是當時投資人和客戶最常問的問題。
孤獨的先知
在 ChatGPT 爆發之前的歲月裡,Groq 是一個孤獨的異類。
當時的 AI 市場由「訓練」主導。訓練需要的是吞吐量(Throughput),是讓貨車一次拉最多的貨。Nvidia的 GPU 是為此而生的王者。
而 Groq 專注的是「推理」的延遲(Latency),也就是法拉利送貨的速度。那時,沒有人需要法拉利。
大家都在做離線的數據分析,晚上把數據丟進去,第二天早上看結果,快一秒慢一秒根本沒人在乎。
在這段時間中,根本沒人關心推理。投資人看不懂為什麼要追求極致的低延遲,客戶也不在乎 0.2 秒和 1 秒的區別。Groq 曾數次瀕臨破產,Ross 甚至不得不自掏腰包維持公司運轉。
Jonathan Ross 和他的團隊在沒有掌聲的舞台上堅持了八年。他們被嘲笑為「偏科生」,被質疑技術路線走進了死胡同。他們製造了一把屠龍刀,卻發現世界上只有殺雞的需求。
直到 2022 年底,OpenAI 發布了 ChatGPT。
一夜之間,世界變了。AI 不再是後台的批處理任務,變成了前台的即時對話。用戶開始在乎每一個字的生成速度。延遲成為了新的痛點。
Groq 等待的風,終於來了。
這家「離經叛道」的公司,終於迎來它命運的轉折點。
第三章:速度的證明與資本的狂歡
在很長一段時間裡,Groq 面臨著一個典型的硬體初創公司困境:你的晶片再好,如果開發者拿不到手、不會用,那也是廢鐵。
傳統的銷售模式是將實體 LPU 卡賣給數據中心,但這意味著漫長的交付週期、複雜的硬體適配和高昂的試錯成本。對於那些渴望速度的 AI 開發者來說,這太慢了。
於是,在 2024 年初,Groq 做了一個大膽的決定——如果我們不賣鏟子,而是直接提供挖好的金礦呢?
這就是 GroqCloud。

簡單來說,GroqCloud 是一個推理即服務(Inference-as-a-Service)平台。Groq 將數千張 LPU 卡架設在自己的數據中心裡,並封裝成簡單易用的 API 接口。
開發者不需要購買任何硬體,不需要懂底層編譯原理,只需要像調用 OpenAI 的 API 一樣,將模型請求發送給 GroqCloud,就能立刻體驗到 LPU 的極致速度。
這一轉變是革命性的。它將原本需要幾個月的硬體部署週期,壓縮到了幾秒鐘的 API 調用。
碾壓級的基準測試:碾壓 H100
隨著 GroqCloud 的開放,以及那條引爆全世界的推文之後,開發者開始對它進行瘋狂的壓力測試。結果是令人瞠目結舌的。
在知名 AI 評測機構 Artificial Analysis 的榜單上,Groq 的數據點孤零零地懸掛在圖表的左上角——那是代表「極致速度」和「極致低價」的無人區。

速度對比: 當時最強大的 Nvidia H100 GPU 在運行 Llama 2 70B 這種主流大模型時,輸出速度大約是每秒 30-50 tokens。而 Groq 的 LPU 在同樣的 70B 模型上跑出了每秒約 270-300 tokens 的速度,是 H100 的 6 到 10 倍。而在運行 Gemma 7B 等輕量級模型時,Groq 更是飆升至每秒 800 tokens 以上。
延遲對比: 對於語音對話來說,人類能感知的延遲極限大約是 200 毫秒。GPU 的推理延遲通常在 500 毫秒以上,導致對話總有尷尬的停頓。而 Groq 將這個數字壓到了 100 毫秒以內。
這意味著什麼?這意味著 AI 終於可以像真人一樣說話了。
實際應用場景:誰在為速度買單?
這種極致的速度不僅僅是為了炫技,它解鎖了那些 GPU 無法觸及的商業場景。
獨角獸的選擇:
Canva: 這家擁有 2.6 億月活用戶的設計巨頭,並沒有選擇傳統雲廠商,而是將其 AI 魔法設計功能的後端推理交給了 Groq,只為了讓用戶在點擊「生成」的那一瞬間無需等待。
GPTZero: 擁有 1000 萬用戶的 AI 抄襲檢測工具,利用 Groq 將檢測速度提升了 7 倍,同時保持了 99% 的準確率。
即時語音助手: 像 Vapi 和 Retell AI 也在和Groq商討合作。過去,和 AI 打電話像是在用對講機,你說完,等一秒,它再回。現在,AI 可以隨時打斷你,插話,甚至和你吵架,流暢得令人恐懼。
即時翻譯: 在聯合國會議或跨國商務談判中,Groq 讓「同聲傳譯」變成了真正的「同步」。
資本的狂歡:從 2.8 億到 69 億到 200 億的飛躍
速度的證明直接引爆了資本市場的熱情。
Groq 的融資歷程是一條完美的指數曲線。早期,只有像 Chamath Palihapitiya 的 Social Capital 這樣大膽的風險投資人敢於下注。但在 2024 年那場病毒式的傳播之後,華爾街的「聰明錢」也開始進場了。
2025年9月,Groq 完成了新一輪融資,由 BlackRock(貝萊德) 領投,估值達到69億美元。這份投資名單堪稱豪華:思科 (Cisco)、三星 Catalyst Fund,甚至還有小Donald Trump的1789 Capital。
這傳遞了一個明確的信號:Groq 不再是一個科學實驗,它是被視為能夠挑戰Nvidia霸權的戰略資產。投資人看懂了一件事——如果推理(Inference)是 AI 的未來,那麼 Groq 會在這個未來有一席之地。
孤獨的戰士們:為什麼是 Groq?
Groq 並不是唯一試圖推翻Nvidia統治的反抗軍。在矽谷的各個角落,還有其他強大的挑戰者:
Cerebras: 他們造出了世界最大的晶片(Wafer Scale Engine),一塊晶片就有一張餐桌那麼大,試圖用暴力美學解決訓練問題。
SambaNova: 由史丹佛大學教授創立,主打可重構數據流架構,深受企業級客戶喜愛。
Tenstorrent: 由傳奇晶片設計師 Jim Keller 領軍,試圖用 RISC-V 架構重寫規則。
然而,在 2024 年至 2025 年的這段時間窗口裡,Groq 顯得最為特別。
為什麼?因為其他挑戰者大多還是在解決「訓練」的問題,或者試圖做一個「更好的 GPU」。只有 Groq,極端地、偏執地只解決一個問題:推理的延遲。
第四章:200 億美元的聖誕震撼
2025 年 12 月 24 日,矽谷的聖誕夜並不平靜。
當大多數人正準備與家人拆禮物時,一條重磅新聞推送震動了整個科技圈:Nvidia宣布以 200 億美元現金,與 Groq 達成「戰略合作協議」。
新聞稿的措辭經過了精心雕琢,每一個字都像是在法律的鋼絲上跳舞。
Nvidia發言人強調:「我們正在吸納 Groq 的傑出人才並獲得其技術授權,這不是一次傳統意義上的公司收購。」

