
雲端巨頭為何急需ASIC?博通為何估值比NVDA還高?光通訊是Marvell重要支柱?- 深入分析第38期:Broadcom+Marvell


想像一下,你正坐在Google或Meta的基礎設施決策會議裡。桌上擺著今年剛被董事會批准的龐大資本支出(CapEx)預算:一個高達千多億美元的鉅額數字。
你的任務是建置下一個世代的 AI 叢集,規模是十萬顆運算晶片起跳。如果你選擇全部採購市面上最頂級的通用型 GPU,你會立刻撞上「金錢與能源的極限」。
在單一資料中心裡塞進十萬顆頂級 GPU,你面臨的不僅是每顆動輒數萬美元的硬體採購成本,更致命的是,你根本無法從當地的電網牽出足夠的百萬瓦(Megawatts)電力來支撐這些高功耗硬體的運作,更別提隨之而來的龐大液冷散熱需求。
這就是為什麼在 2026 年的今天,對雲端巨頭們來說,走向 Custom ASIC(客製化晶片)早已是必須的選項。
然而,當市場的鎂光燈全數聚焦在 Nvidia 身上時,多數投資人忽略了支撐這場 AI 革命的真正骨幹。
沒有極速的網路傳輸,再強大的 AI 晶片也只是無法溝通的孤島;沒有頂級的實體設計能力,巨頭們的自研晶片藍圖永遠只能停留在紙上。
這造就了兩家在 AI 基礎設施領域具備統治級地位的半導體巨頭:Broadcom(博通)與 Marvell(邁威爾)。
在這份深度產業分析報告中,我們將帶您跳脫表面的財報數字,深入 AI 硬體的底層邏輯。您將在本文中了解到:
ASIC 經濟學的底層邏輯:為什麼 CSP 巨頭寧願耗資數億美元,也要擺脫對通用 GPU 的單一依賴?
深潛核心技術護城河:白話解析 SerDes、PAM4 DSP 與光子互連技術,看懂這兩大巨頭如何壟斷 AI 數據的高速公路。
Broadcom 的雙引擎防禦力:解析執行長 Hock Tan 如何透過「半導體+軟體」架構,打造抵禦 CapEx 週期的終極現金流機器。
Marvell 的高爆發成長飛輪:探討其如何透過「XPU Attach」戰略與光通訊霸權,滲透進所有雲端巨頭的供應鏈。
雙雄對決與投資終局推演:在壓力情境下的韌性測試,以及基於 2026/2027 年最新估值的投資邏輯拆解。
第一部:產業底層邏輯與技術深潛——為什麼 CSP 巨頭離不開他們?
第一章:ASIC 經濟學的殘酷真相——當 GPU 成為規模化的「毒藥」
市場多數人都知道 GPU 是「通才」,ASIC 是「專才」,但這在晶片底層到底意味著什麼?
1.1 剝開晶片外衣:GPU 的「暗矽(Dark Silicon)」與效能浪費
一顆頂級的通用 GPU,是人類工程史上的奇蹟,它被設計來應付全世界所有客戶的千奇百怪需求,從高頻交易、氣象模擬、科學運算,到各種類型的 AI 模型。
為了保持這種「通用性」,GPU 的裸晶(Die)上必須保留大量的電晶體,用來支援各種不同的精度格式(FP64、FP32 等)、圖形渲染管線,以及複雜的排程邏輯。
然而,當 Google 或 Meta 只是想要日復一日、年復一年地運行他們已經架構固定的 Transformer 模型(如 Gemini 或 Llama 3)時,GPU 上有越來越高比例的電晶體是完全派不上用場的。
在半導體業界,這被稱為「暗矽(Dark Silicon)」。
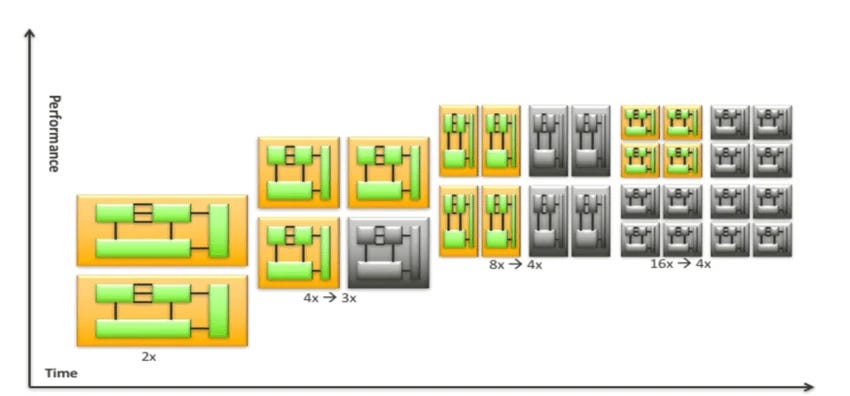
在 3 奈米或更先進的製程下,這些閒置的暗矽即使不運算,依然會產生漏電流(Leakage Power)。在十萬顆晶片的規模下,這些無用的電晶體每年會產生龐大的額外電力成本。
相反地,Custom ASIC 的設計哲學是「極簡與專注」。巨頭們可以大刀闊斧地砍掉所有不需要的邏輯單元,將省下來的珍貴晶片面積,全部換成 AI 運算最渴望的資源:SRAM(靜態隨機存取記憶體)與矩陣乘法單元。
這種「為單一演算法量身訂做」的架構,讓 ASIC 能在相同的功耗限制下,釋放比 GPU 高出 30% 到 50% 的吞吐量,同時將單次推論的成本(Cost per Token)壓到最低。
1.2 2026 年的市場版圖:從「推論」走向「全面接管」
如果我們檢視 2026 年的最新市場數據,會發現 ASIC 的滲透速度遠超過去幾年的華爾街預期。
根據 TrendForce 與業界機構的估算,2024 年客製化 AI ASIC 的總潛在市場(TAM)大約落在 180 億美元;但到了 2026 年,這個數字已經膨脹到 300 億至 400 億美元的規模,並預計在 2027 年出貨量比 2024 年實現三倍成長的目標。在 2026 年出貨的所有 AI 伺服器中,搭載 ASIC 的比例已經逼近 28%。
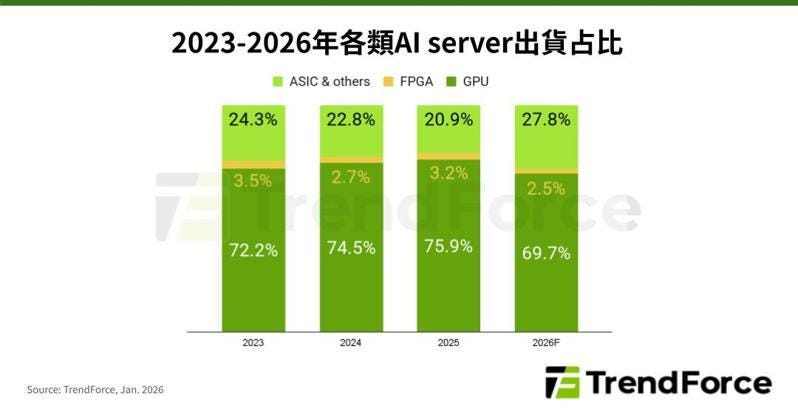
更關鍵的質變在於「應用場景的擴張」。
過去,市場普遍認為 ASIC 只適合用來做「推論(Inference)」,而高難度的「訓練(Training)」依然是 Nvidia GPU 的天下。但在 2026 年,這個界線已經被打破,以 Google 的訓練有不少也是用自家TPU。
不只是 Google,Amazon 的 Trainium、Microsoft 的 Maia,甚至連沒有自家雲端基礎設施的純 AI 實驗室(如 OpenAI 與 Anthropic),都在 2026 年確認了 Gigawatt(十億瓦)級別的客製化晶片部署計畫。
1.3 巨頭的終極算盤:奪回定價權
說到底,捨棄 GPU 轉向 ASIC,是雲端巨頭們的一場「主權保衛戰」。
當 AI 算力成為未來十年的核心基礎資源,沒有任何一家市值數兆美元的 CSP,會願意將自己核心基礎設施的毛利率與發展節奏,完全交給單一家 GPU 供應商來決定。
透過自研 ASIC,他們不僅能將硬體成本從「被動接受的零售價」轉變為「可控的製造成本」,更能將軟體生態系與底層硬體深度綁定,築起極高的客戶轉換壁壘。
然而,Google 懂演算法,Meta 懂社群數據,微軟懂作業系統。但當他們拿著完美的 AI 架構圖,轉身面對台積電 3 奈米產線上那動輒數百億個電晶體的物理極限、訊號干擾與封裝難題時,他們發現自己根本無法獨自跨越這道硬體製造的鴻溝。
這,就是 Broadcom 與 Marvell 能夠在 AI 時代建立起兆元帝國的真正起點。
第一章小結:ASIC 經濟學的殘酷真相
GPU 的效能浪費:通用 GPU 為了支援多樣化需求保留了大量「暗矽(Dark Silicon)」,在運行特定 AI 模型時會產生龐大的無謂能源耗損。
ASIC 的極簡優勢:客製化晶片專注於 SRAM 與矩陣乘法,能在相同功耗下釋放更高吞吐量,並大幅降低單次推論成本。
應用場景全面擴張:2026 年 ASIC 已打破「僅限推論」的刻板印象,全面進軍高階訓練領域,總潛在市場(TAM)上看 400 億美元。
奪回供應鏈主導權:雲端巨頭轉向 ASIC 的核心戰略,是為了將硬體成本轉為可控,並將軟體生態與底層硬體深度綁定。
第二章:巨頭為甚麼要找幫手?
Google、微軟和 Amazon 這麼有錢,市值動輒數兆美元,軟體工程師都是全世界最頂尖的天才,為什麼他們不乾脆自己把晶片做出來,還要讓 Broadcom 或 Marvell 賺走這筆豐厚的利潤?
這個問題的答案,藏在半導體產業的「物理現實」與「試錯成本」之中。
如果用一個簡單的比喻:Google 就像是一位擁有米其林三星配方的頂級主廚(懂 AI 算法與架構),他知道這道菜需要什麼樣的火候與食材。
但 Broadcom 則是那個知道如何用最高級的合金、在極端高溫下鍛造出一口「受熱絕對均勻且永不變形」的頂級鍋具工匠。
一顆現代 AI ASIC,其實只有 30-40% 是 CSP 自家設計的 AI 運算邏輯(大腦),剩下的 60-70% 全是基礎設施(管線,如 SerDes、PCIe、記憶體控制器)。
在 2026 年的 AI 晶片戰場上,硬體製造與實體設計的門檻,已經高到連科技巨頭都難以單獨跨越。
2.1 實體設計的極限挑戰:從邏輯到物理的鴻溝
雲端巨頭(Hyperscalers)的強項在於「邏輯設計」。他們非常清楚自家的 AI 模型(如 Gemini 或 Llama)需要多大的矩陣乘法單元、需要多大的 SRAM,以及資料流應該如何走最有效率。他們可以寫出完美的 RTL(暫存器傳輸級)程式碼。

但真正的挑戰,是將這些邏輯代碼轉化為台積電 3 奈米(甚至未來的 2 奈米)產線上的實體藍圖。
在 3 奈米的微觀世界裡,一顆 AI 晶片上擠著數百億、甚至上千億個電晶體。當這些電晶體同時以極高的時脈運作時,會產生嚴重的物理問題:
漏電與熱點(Thermal Hotspots): 晶片某些區域會因為運算過於密集而產生極高溫,如果實體佈線(Floorplanning)設計不良,晶片會直接燒毀或降頻。
訊號完整性(Signal Integrity): 在奈米級的線路中,電子訊號會互相干擾(Crosstalk)。
先進封裝的良率: 2026 年的頂級 ASIC 已經不是單一裸晶,而是依賴台積電的 CoWoS 或 3D SOIC 技術,將邏輯晶片與 HBM(高頻寬記憶體)封裝在一起。這需要極度精密的熱膨脹係數計算與應力測試。
Broadcom 與 Marvell 擁有數千名專注於「實體設計(Physical Design)」與「後端驗證」的硬體工程師。
他們知道如何把巨頭們的邏輯藍圖,完美地擺放進矽晶圓裡,並確保交給台積電製造時,能擁有極高的良率。這是一項高度依賴長期經驗累積的深層工程技術。
2.2 IP 積木與專利牆:不容試錯的造橋工程
設計一顆現代 AI 晶片,就像是用樂高積木蓋一座摩天大樓。除了核心的 AI 運算單元外,晶片還需要無數的「基礎零件」,在業界稱為 IP(矽智財)。

這些 IP 包括:讓晶片與外部溝通的 PCIe 介面、控制 HBM 的記憶體控制器,以及最重要的核心樞紐:負責超高速數據傳輸的 SerDes(我們將在下一章深入探討)。
Broadcom 與 Marvell 擁有全世界最齊全、且「已經過台積電最新製程驗證」的頂級 IP 庫。如果 Google 或 Amazon 想要完全踢開他們、從零開始自研,意味著每一塊基礎積木都要自己重新發明。
這不僅需要耗費 5 到 10 年的時間,更可怕的是「試錯成本」。在 3 奈米製程下,光是一套光罩(Mask)的成本就高達數千萬美元。
如果巨頭自己設計的記憶體控制器有瑕疵,導致整批價值數億美元的晶片報廢,損損失的不僅是金錢,更會導致錯失整整一年的 AI 部署時機。
因此,巨頭們最理性的商業決策是:專注於自己擅長的 AI 架構,然後付錢給 Broadcom 或 Marvell,直接使用他們已經驗證過、具備高度可靠性且經量產驗證的 IP 模組。
2.3 護城河拆解:Broadcom 與 Marvell 各自不可替代的理由
在深入探討底層技術之前,我們必須先釐清一個核心問題:為什麼是 Broadcom 和 Marvell?為什麼不是賣 EDA 工具的 Synopsys 或 Cadence?又為什麼不是世芯(Alchip)等較小的 ASIC 設計廠?
答案在於「規模」與「系統級的整合」。Synopsys 只賣工具不包設計;小型 ASIC 廠缺乏最頂級的自有 IP 庫與台積電的絕對優先產能。要看懂這兩大巨頭的統治力,我們可以直接對標 Nvidia:
Nvidia 的護城河是「CUDA 軟體生態 + 最強 GPU 矽 + 全棧系統(DGX + NVLink)」。
Broadcom 的護城河則是「三位一體的不可替代性」:
先進製程實體設計能力: 這不僅是硬核工程,更是「複利優勢」。每一次在台積電 3nm/2nm 的成功流片,都化為內部工程師腦中與專有 EDA 流程裡「不可轉移的機構知識」。CSP 若想自己來,得先花 5 到 10 年付出慘痛的試錯成本。
業界最完整的矽智財(IP)軍火庫: 涵蓋那 60-70% 的晶片管線。客戶找 Broadcom,等於所有基礎設施都能「隨插即用」,且保證在台積電最新製程上絕對不出錯。
交換機晶片的生態系統霸權: 這是 Broadcom 獨有的核心競爭力。他們不只做單顆 ASIC,還擁有將十萬顆晶片連成網路的 Tomahawk 交換機。他們能進行「晶片+網路」的系統級協同最佳化,這是任何對手都無法完整複製的。
Marvell 的護城河則是「光與電的翻譯者」:

PAM4 DSP 的絕對統治: 當 AI 叢集從一萬顆擴張到一百萬顆,網路晶片的需求增長速度遠大於運算晶片。每一條光纖裡的光訊號都需要 Marvell 的 DSP 來編碼解碼,這是一個比算力更強勁的結構性順風。
客製化 ASIC 的「第二選擇」優勢: 市場主動需要 Marvell 存在。沒有理性的採購長會讓 Broadcom 徹底壟斷,Marvell 是唯一具備頂級實力且能作為戰略制衡的第二供應商。
光學互連的垂直整合: 從電氣 SerDes 到 DSP 再到光學 PHY,Marvell 掌握了邁向未來 CPO/LPO 時代的最完整光電技術棧。
第二章小結:巨頭為甚麼要找幫手?
實體設計的物理鴻溝:將邏輯代碼轉化為 3 奈米實體晶片,需克服漏電、訊號干擾與先進封裝等極高難度的工程挑戰。
IP 模組的專利壁壘:Broadcom 與 Marvell 掌握經過台積電驗證的頂級 IP 庫,巨頭若自研將面臨極高的時間與試錯成本。
Broadcom 的護城河:具備先進製程實體設計的複利優勢、最完整的矽智財軍火庫,以及交換機晶片的系統級生態霸權。
Marvell 的護城河:掌握光通訊 PAM4 DSP 的絕對統治力,並作為市場制衡 Broadcom 的唯一頂級「第二選擇」。
第三章:SerDes 是什麼?為什麼它這麼重要?
在探討 AI 基礎設施時,我們常常把目光聚焦在算力有多強、晶片有多大。你可以把 Nvidia 的 GPU 或 Google 的 TPU 想像成一顆顆擁有極高智商的「天才大腦」。然而,在 2026 年動輒由十萬顆晶片組成的 AI 叢集中,如果這些天才大腦之間無法快速溝通,整體運算效能將大幅受限。
這就是 AI 時代最致命的瓶頸:頻寬(Bandwidth)。如果運算核心算得再快,但資料卻堵在晶片門口出不去,這顆昂貴的晶片就只能在原地空轉等資料。
為了解決這個問題,半導體界發展出了一項極度硬核、且專利壁壘極高的技術。它就是 Broadcom 與 Marvell 能夠稱霸兆元 AI 帝國的關鍵技術壁壘:SerDes。
3.1 數據的高速公路:為什麼我們需要 SerDes?
SerDes(發音近似 “Sir-Dees”)是 Serializer(序列器)與 Deserializer(解序列器)的合稱。簡單來說,它是數位世界裡的「高速傳送門」與「翻譯官」。
要理解它的偉大,我們必須先明白晶片內外傳輸的根本差異。

想像你要把 64 個包裹,從 A 工廠(晶片內部)送到 B 工廠(另一顆晶片或記憶體)。
並列傳輸(Parallel): 在晶片內部,空間相對寬裕,你可以蓋 64 條平行的短馬路,讓 64 輛車同時出發。優點是一次能送很多;缺點是極度佔用實體空間(晶片邊緣的腳位有限),且馬路長度必須分毫不差,否則車子抵達時間不同,資料就會大亂。此外,線路靠得太近還會產生嚴重的電磁干擾。
序列傳輸(Serial): 當資料要「跨出」晶片時,我們無法拉出 64 條實體銅線。這時,我們改蓋一條「超高速的高鐵隧道」,讓這 64 個包裹排成一列,以極限速度單線衝刺過去。這不僅節省了寶貴的實體空間,也不怕抵達時間不一致的問題。
然而,要把並排的資料變成單線衝刺,你需要一個極度強悍的「打包員」在起點把東西排好,以及一個聰明的「拆解員」在終點把東西完美還原。這就是 SerDes 的工作。
3.2 深入運作機制:從「一坨爛泥」中找回真相
SerDes 的運作機制,堪稱現代電子工程的奇蹟。它的工作可以拆解為三個極具挑戰的階段:

傳送端:序列化(Serialization)
晶片內部的資料是並列處理的。SerDes 的第一步,是利用一個頻率極高的「時鐘(Clock)」來指揮,將這些並列的位元(Bits)像軍隊排隊一樣,精準地塞進一條細細的傳輸線裡,化為單線訊號射出。傳輸過程:物理極限的摧殘(The Channel)
當資料以每秒幾十 GB,甚至在 2026 年達到 112G 或 224G(每秒 2,240 億個位元)的極速在銅線或電路板上狂奔時,會遭遇嚴酷的物理考驗:衰減(Attenuation): 跑得越遠,訊號的能量就越弱。
雜訊與干擾(Noise & Crosstalk): 旁邊的電子零件與線路會不斷干擾它。
反射(Reflection): 訊號碰到接頭或阻抗不匹配的地方,會像水波一樣反彈回來。
經歷了這些摧殘,原本在起點方方正正、乾淨俐落的數位訊號(0 和 1),到了終點時,在示波器上看起來已經變成像「一坨爛泥」般的模糊波形。
接收端:解序列化(Deserialization)
這是 SerDes 展現真正技術壁壘的時刻。它必須從那坨爛泥中,重新辨識出誰是 0、誰是 1。時鐘資料復原(CDR, Clock Data Recovery): 接收端沒有人告訴它節奏,它要透過複雜的演算法,從微弱的訊號變化中精準還原時脈
等化器(Equalization): 這是 SerDes 內部的「美圖秀秀」。它會透過複雜的類比與數位電路,把模糊不清的訊號重新「拉皮、銳化」,讓 0 和 1 的邊界重新變得清晰。
還原: 最後,把排隊的資料重新拆開,還原成原本的並列資料,交給接收端的晶片處理。
3.3 技術壁壘與 224G 的極限挑戰
你可能會問,既然原理都公開了,為什麼只有少數幾家公司做的好?因為在 112G 與 224G 的極速下,遊戲規則已經改變。
為了達到這種極限傳輸速率,業界從傳統的 NRZ(PAM2) 技術進化到了 PAM4。

過去的 NRZ: 訊號只有「高」和「低」兩種電壓,代表 0 和 1。一次只能傳 1 個位元。這就像是一台只能載 1 個人的單車。
現在的 PAM4: 訊號細分為四種高度(00, 01, 10, 11)。這就像在同樣的時間內,單車變成了「雙載機車」,速度直接翻倍。
但代價是,四個電壓等級分得太細,訊號變得極度脆弱,稍微有一點點雜訊,01 就會被誤判成 10。要在一秒鐘內處理千億次這種微小差異,且保證「零失誤」,這需要深不見底的類比電路(Analog Circuit)設計功力。
更致命的是「功耗與散熱」。
SerDes 跑得越快,晶片就越燙。在一個 AI 伺服器機櫃裡,有成千上萬條 SerDes 連線在同時運作。
如果 SerDes 設計得不夠好,晶片將近一半的電力都會被浪費在「傳輸資料」上,導致真正用來「計算 AI 模型」的電力被嚴重排擠,甚至讓整台伺服器熱到當機。
3.4 雙雄的統治力:為什麼是 Broadcom 與 Marvell?

Broadcom 是業界無可爭議的「黃金標準」。 這正是我們前面提到「最完整 IP 軍火庫」護城河的核心體現。
他們的 112G 與最新的 224G SerDes IP,能在極限速度下,保持出色的「低功耗」與「高穩定性」。
當 Google 或 Meta 在設計下一代 ASIC 時,他們不敢拿價值數億美元的專案去賭其他二線廠的 SerDes,直接採用 Broadcom 經過台積電 3nm/2nm 驗證的 IP,是唯一能保證準時量產且不出錯的選擇。

Marvell 則在「光學傳輸」上具備統治力。 當資料傳輸的距離拉長(例如跨越機櫃),銅線的物理極限就會被打破,必須將電訊號轉換為光訊號。
Marvell 憑藉著其在 PAM4 DSP(數位訊號處理器)的絕對領先地位,成為了光通訊模組裡的大腦。沒有 Marvell 的 DSP,光纖裡的光訊號就無法被精準地編碼與解碼。
第三章小結:核心技術解密——SerDes
突破頻寬瓶頸:SerDes 是晶片間高速序列傳輸的核心樞紐,負責將並列數據序列化以跨越晶片邊界,並在接收端精準還原。
極限物理挑戰:在 224G 的極速下,訊號衰減與干擾極為嚴重,需要極其深厚的類比電路設計底蘊來進行時脈復原與訊號等化。
PAM4 技術的代價:為提升傳輸率採用的 PAM4 技術使訊號變得極度脆弱,且高速運作伴隨嚴重的功耗與散熱問題。
雙雄的技術統治力:Broadcom 在銅線 SerDes IP 具備低功耗與高穩定性的黃金標準;Marvell 則將此技術延伸至光纖,稱霸光通訊 DSP。
第四章:從 SerDes 到產品霸權——Broadcom 的交換機帝國與 Marvell 的光通訊統治
在上一章,我們深入了 SerDes 的微觀世界,看見了它如何在一秒鐘內處理千億次訊號、從「一坨爛泥」中還原出精確的數位真相。
但技術本身不會變成護城河。真正讓 Broadcom 與 Marvell 在 AI 時代建立起兆元帝國的,是他們如何將這項「根源技術」,延伸成對手無法複製的完整產品生態。
4.1 Broadcom 的 Tomahawk:當 SerDes 變成「十萬顆晶片的交通總指揮」
在 2026 年的超大規模 AI 叢集中,十萬顆運算晶片必須像一支紀律嚴明的軍隊般同步運作。每一顆晶片算出來的結果,都必須在極短的時間內傳送給其他所有晶片。如果網路出現哪怕一瞬間的壅塞或延遲,數千顆晶片就會在那裡空轉等資料——每一秒的閒置,都是數萬美元的電費在燒。
負責指揮這場數據交通的核心元件,就是交換機晶片(Switch ASIC)。而 Broadcom 的 Tomahawk 系列,是這個領域無可爭議的王者。
Tomahawk 的統治力從何而來?答案就藏在上一章的技術裡。

打開 Broadcom 最新的 Tomahawk 6 交換機晶片,你會發現它的內部塞滿了數百條自家最頂級的 224G SerDes 通道。
正是這些 SerDes 的極限速度與超低功耗,讓 Tomahawk 6 能夠實現驚人的 102.4 Tb/s 總吞吐量,相當於每秒能搬運超過一千萬部高畫質電影的數據量。
但 Tomahawk 的護城河,遠不只是「跑得快」。
真正讓對手無法複製的核心競爭力,是 Broadcom 獨有的「晶片+網路」垂直整合。請想像這個場景:當 Google 找 Broadcom 設計下一代 TPU 時,這顆客製化 ASIC 裡面用的是 Broadcom 的 SerDes IP;而當這顆 TPU 需要透過網路與其他十萬顆 TPU 溝通時,負責轉發數據的交換機裡,裝的也是同一家 Broadcom 設計的 SerDes。
這意味著什麼?從晶片的內部到晶片之間的網路,整條數據高速公路的「引擎」都是同一個工程師團隊調校出來的。
Broadcom 能夠在系統層級進行端對端的協同最佳化——調整 ASIC 端的傳輸參數,讓它完美匹配交換機端的接收特性,反之亦然。
這種跨越「運算」與「網路」的系統級整合能力,是任何只做 SerDes IP 授權(如 Alphawave)、或只做 EDA 工具(如 Synopsys)的公司,根本無法觸及的維度。

在通訊協定的選擇上,2026 年的大趨勢已經非常明確:由 Broadcom、微軟、Meta、AMD 等巨頭主導的「超級乙太網聯盟(UEC)」在 2025 到 2026 年取得了決定性進展,讓開放的乙太網路(Ethernet)成為主流。簡單來說,沒有任何一家市值數兆美元的雲端巨頭,願意讓自己核心基礎設施的網路層也被 Nvidia 一家壟斷。而 Broadcom 的 Tomahawk,正是這場「開放陣營逆襲」中最大的軍火供應商。
值得注意的是,Nvidia 並非坐以待斃。其 Spectrum-X 平台正試圖將 InfiniBand 的軟體定義優勢移植到乙太網路上,同時透過 NVLink 的持續升級將叢集內互聯的頻寬天花板不斷拉高。如果 Nvidia 成功讓客戶在乙太網路上也離不開其軟體堆疊,Broadcom 在網路層的結構性優勢將面臨比本文所描述的更大壓力。
4.2 Marvell 的光通訊統治:當銅線走到盡頭
Broadcom 用 SerDes 征服了交換機的世界,但這個世界有一個物理極限:銅線傳不遠。
在上一章我們提到,當 SerDes 的速度飆升到每通道 224G 時,電子訊號在銅線中遭受的衰減、干擾與反射變得極其劇烈。
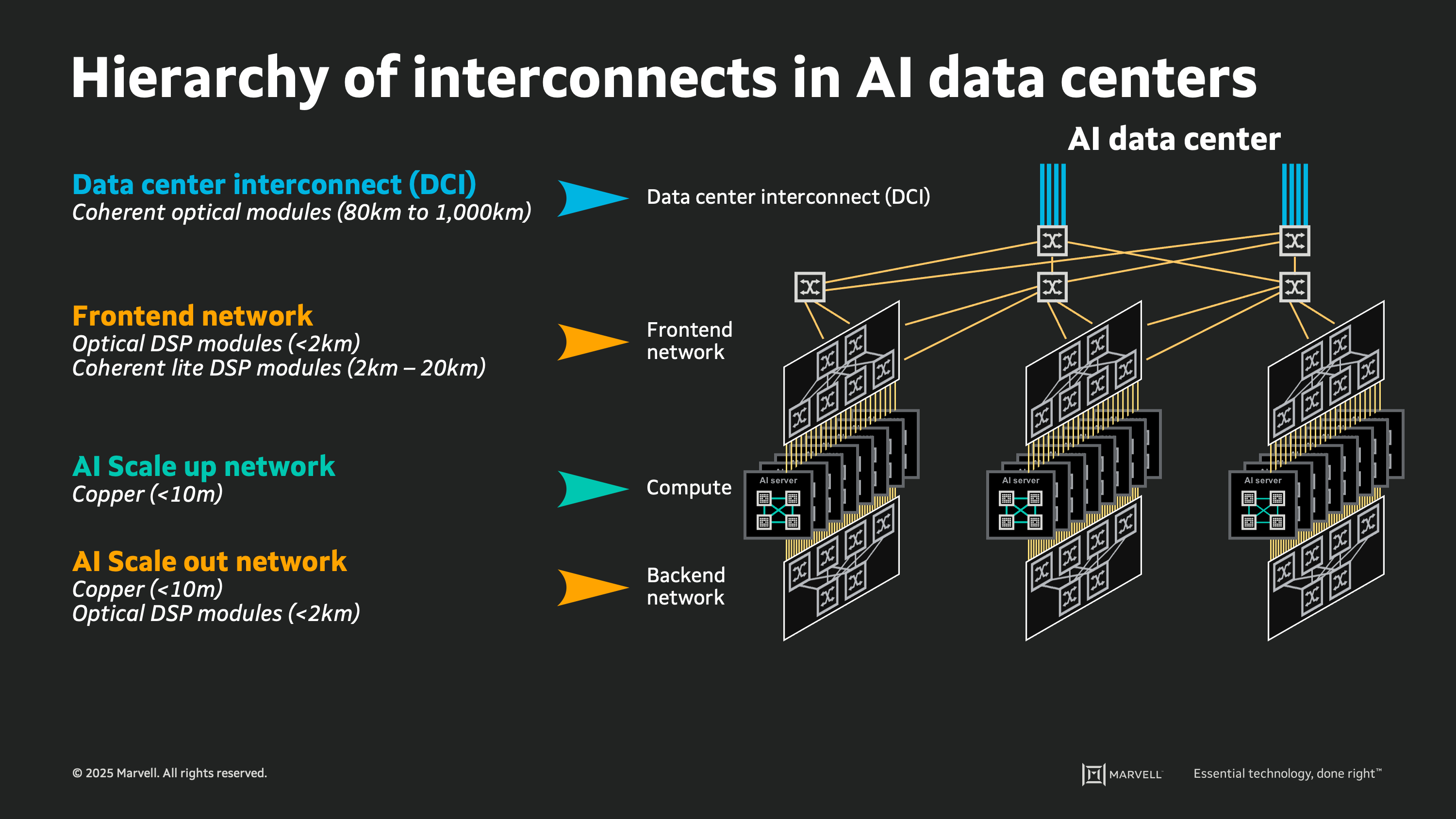
在這個極速下,銅線的有效傳輸距離已經縮短到不到一公尺。這意味著,只要兩台伺服器稍微離得遠一點——跨越機櫃、跨越機房——銅線就徹底失效了。
在十萬顆晶片的 AI 工廠裡,不可能把所有伺服器都擠在一公尺的範圍內。當數據必須跨越數十公尺甚至數公里時,唯一的解法就是把電變成光。
光通訊模組的作用,就是在伺服器的出口,把晶片算出來的電子訊號轉換成雷射光訊號,透過光纖射到另一端的機櫃,然後再把光轉換回電。光不受電磁干擾,傳輸距離可以長達數公里,且頻寬潛力遠大於銅線。
而在這個「光與電的翻譯」過程中,需要一顆極度複雜的晶片來處理訊號的編碼、等化與復原——這就是 PAM4 DSP(數位訊號處理器)。
如果你理解了上一章 SerDes 的運作原理,那麼理解 Marvell 的 PAM4 DSP 就非常直覺:它本質上就是「光纖版的 SerDes」。 差別只在於,傳輸的媒介從銅線變成了光纖,而訊號的載體從電子變成了光子。
正是這種在高速訊號處理上數十年的技術累積(主要源自 Marvell 對 Inphi 的關鍵收購),讓 Marvell 在 800G 光模組的 DSP 市場中握有高達 70% 到 80% 的統治級市佔率。到了 2026 年,他們更是市場上第一家量產 1.6T(採用 2 奈米製程)相干 DSP 的廠商,成功打入美國全部五大雲端巨頭的供應鏈。
這個市場有多大?根據最新的產業數據,800G 與 1.6T 光模組在 AI 叢集中的滲透率,預計在 2026 年將突破 60%(相較於 2024 年的不到 20%)。這是一條幾近垂直的爆發曲線——而 Marvell 的 DSP,就坐在這條曲線的正中央收取「過路費」。
4.3 同一個引擎,兩座帝國
讓我們退後一步,重新審視 Broadcom 與 Marvell 的技術護城河全貌。
SerDes 是兩家公司所有產品線的共同技術根源。 但如果你只看到 SerDes,就會低估他們的統治力。真正讓對手無法複製的,是他們各自將這個根源延伸成了完整的產品生態系統:
Broadcom 從 SerDes 出發,向上延伸成了 Tomahawk 交換機的生態霸權,向下延伸成了客製化 ASIC 的全套統包服務。
當一家雲端巨頭選擇了 Broadcom,它買到的不只是一條 SerDes 通道,而是從運算晶片到網路骨幹的系統級整合——這是一個一旦嵌入就極難拔除的飛輪。
Marvell 從 SerDes 出發,將同樣的訊號處理能力投射到光纖的世界,成為了光通訊模組裡不可或缺的大腦。
隨著 AI 叢集從一萬顆擴張到一百萬顆,光纖的需求增長速度遠大於運算晶片本身——每一條新增的光纖,都需要 Marvell 的 DSP 來編碼與解碼。這是一個比算力更強勁的結構性順風。
理解了這些底層的硬核技術與產品護城河後,我們終於可以進入真正的重頭戲:Broadcom 和 Marvell,究竟是如何將這些技術優勢,轉化為華爾街眼中難以撼動的商業帝國與無敵的現金流?
第四章小結:從 SerDes 到產品霸權
Broadcom 的交換機帝國:Tomahawk 系列透過內建頂級 SerDes 實現超高吞吐量,並具備「晶片+網路」的端對端協同最佳化能力。
開放網路的逆襲:由 Broadcom 等主導的超級乙太網聯盟(UEC)在 2026 年迅速擴張,打破 Nvidia InfiniBand 的封閉壟斷。
Marvell 的光通訊統治:當銅線傳輸距離受限,Marvell 憑藉 PAM4 DSP 成為光電轉換的核心大腦,在 800G/1.6T 市場佔據絕對領先。
同源技術的生態延伸:SerDes 技術根源分別被 Broadcom 轉化為網路骨幹與 ASIC 統包服務,被 Marvell 轉化為光通訊與互連霸權。
第二部:Broadcom (AVGO)——無情的併購機器與半導體帝國

在矽谷,大多數的科技巨頭都喜歡談論「改變世界」、「顛覆未來」這類充滿理想主義的願景。但 Broadcom(博通)不同。
這家公司的文化裡沒有太多浪漫的矽谷情懷,取而代之的是華爾街式的冷酷、精準與極致的財務紀律。如果說 Nvidia 是一家由技術狂熱者驅動的創新引擎,那麼 Broadcom 就是一家由頂尖財務工程師與併購大師打造的「極高效率獲利引擎」。
在 2026 年的今天,當我們談論 AI 基礎設施時,Broadcom 已經是與 Nvidia 齊名的雙頭壟斷者。但要理解 Broadcom 為什麼能享有如此高的估值與市場地位,我們必須先理解這座帝國的建立者,以及他那套在科技界前所未見的商業哲學。
Keep reading with a 7-day free trial
Subscribe to FOMO研究院電子報 to keep reading this post and get 7 days of free access to the full post archives.