
HBM DRAM不夠用?NVIDIA 記憶體分層革命? SSD當記憶體? - 深入分析第53期:NAND Flash控制器 (慧榮 SIMO,群聯)


過去大半年,整個 AI 產業都意識到,算力已經不再是唯一的瓶頸。真正卡住所有人、讓運算效率無法提升的,是記憶體。
記憶體晶片不僅容量不夠,而且價格極其昂貴。
在硬體成本高企的今天,如何用更聰明、更省錢的方法解決「記性」的問題,成了所有科技巨頭與新創公司最迫切想解開的謎題。
現在的新方向是,不能只靠堆疊更多昂貴的 HBM 和 DRAM,必須讓相對便宜、容量大的 SSD 扮演更接近記憶體的角色。
這也意味著,SSD 不再只是傳統意義上的儲存裝置,而是被拉進記憶體階層。
在SSD被重新定義的情況下,我們會看到甚麼價值的重新分配?
第一章|AI 的閱讀筆記:KV Cache、Prefill 與 Decode
在早期,AI 的任務很單純,就像一個應付考試的學生,只要負責把書讀熟、把模型練好就行。那時候,大家比的是誰算得快,也就是誰的GPU更強。
但現在,AI 被推上了真實的工作崗位。
它被要求讀完一整本法律合約、要記住一段長達數小時的對話脈絡,甚至要像一個秘書一樣,記得自己前幾步做了什麼。
此時的 AI,不再只是一個快速回答問題的考生,而是一個需要處理堆疊如山卷宗的研究員。
考生的腦袋轉得快就行,但研究員更需要一張足夠大的書桌,以及一套能神速調閱資料的索引系統。
如果書桌不夠大,再聰明的研究員也只能一次讀一頁,效率自然慢了下來。
要看懂這張書桌是怎麼限制 AI 的,我們得先跟著它走一遍工作流程。
1.1 Prefill 與 Decode:兩個截然不同的階段

AI 在接到一段任務時,工作其實被拆成了兩個個性截然不同的階段。
第一階段叫做預填(Prefill)。
這是AI剛拿到大篇幅提示詞的時刻。他需要從頭到尾快速瀏覽一遍,並在旁邊寫下閱讀筆記。
這個動作的特點是需要一次處理極大體積的資料,可以進行高度的平行運算。這正是前述 GPU 利用率衝上九成的黃金瞬間,算力在這裡得到了最充分的釋放。
第二階段叫做解碼(Decode)。
AI開始動筆寫下答案。這裡有一個特別的限制:它每寫下一個新字,都必須回頭把剛剛寫好的筆記重新翻閱一遍,才能決定下一個字該寫什麼。
這個動作只能一個字、一個字接著寫,無法同時進行。此時,晶片不再需要極致的運算速度,它唯一需要的,是能多快把那疊筆記翻過一頁。
這就是為什麼GPU利用率會大幅下跌,因為它一直在等待筆記被搬運過來。
這疊被反覆翻閱的閱讀筆記,在技術上被稱為 KV Cache(鍵值快取)。
KV Cache 的功能非常單純,它把AI讀過每個字所產生的理解記錄下來,如此一來,寫下一個字時就不需要把整本書重新讀一遍。這是一種典型的用空間換取時間的策略,寧可把筆記鋪滿整張書桌,也不要每寫一個字就重讀一次全書。
1.2 KV Cache 與 HBM 的記憶體危機
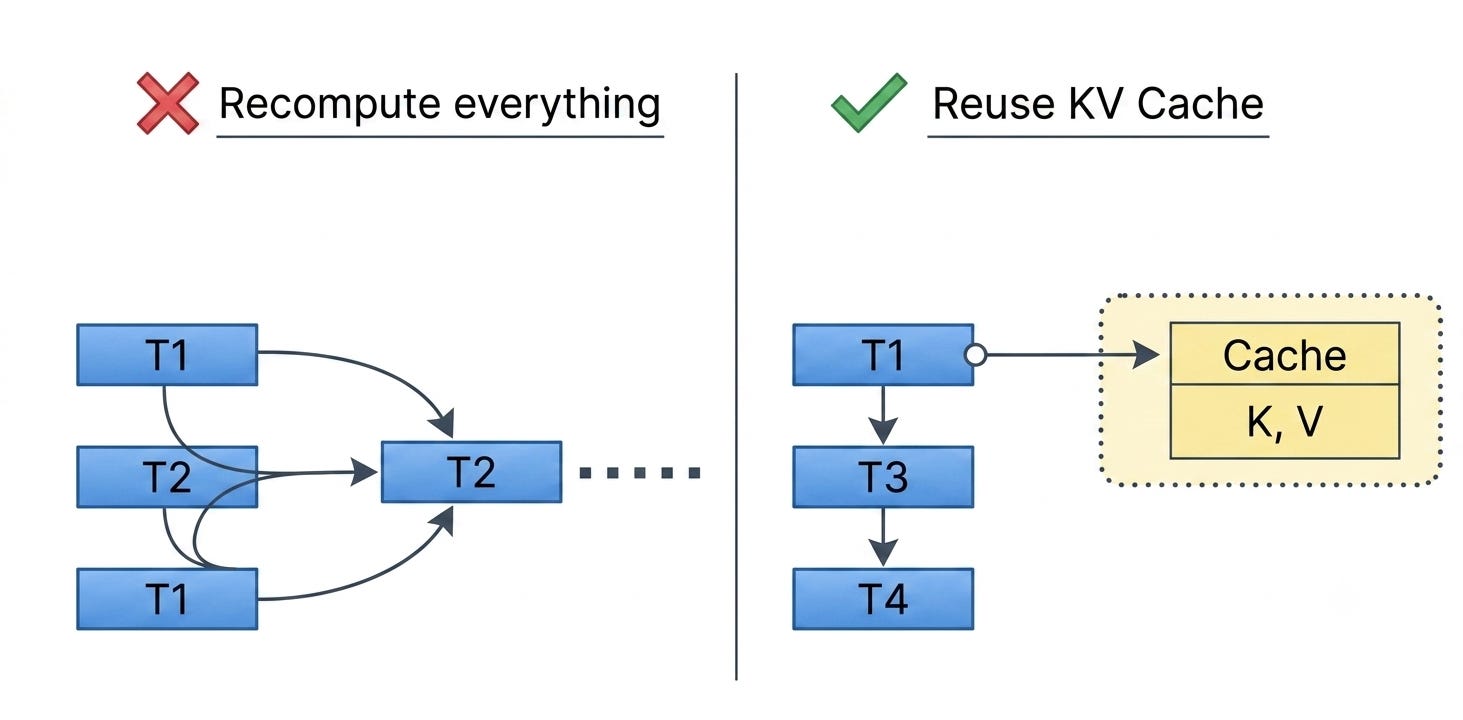
然而,這疊筆記的體積大得超乎想像。光是一段不算長的幾千字對話,產生的筆記就超過1GB。
當我們將這個數字乘上長上下文(動輒幾十萬 Token),再乘上同時在線的成千上萬名使用者時,那塊昂貴且容量極小的 HBM,會在瞬間被這些筆記徹底塞爆。
當手邊的 HBM 裝不下那疊龐大的 KV Cache 筆記時,工程師面臨了兩個選擇。
第一個選擇,是把舊的筆記丟掉。
但如果後面又需要用到,AI 就必須把整本書重新讀一遍、重新做一次筆記。在 AI 的世界裡,重新運算的代價,遠比調閱資料還要昂貴。
因此,如何把筆記暫時收進樓下的地下書庫,並在需要時夠快地拿回來,成了大家努力的方向。
1.3 業界的新方向:預填與解碼分離

第二個選擇,是業界正在嘗試的新架構:預填與解碼分離(Prefill / Decode Disaggregation)。
既然「讀書做筆記」與「逐字寫答案」是兩種完全不同性質的工作,那就不要讓同一顆晶片同時負擔這兩件事。
業界開始把這兩個步驟拆分到不同的伺服器上。負責讀書的專心讀書,負責寫字的專心翻筆記,彼此互不干擾。
這個想法很好,但當我們把做筆記與用筆記的晶片拆開後,那疊厚厚的筆記,就必須在不同的伺服器之間來回高速搬運。
繞了一圈,問題又回到了起點:
這疊永遠放不進 HBM、又絕對不能輕易丟棄的龐大筆記(KV Cache),到底該存放在哪裡,才能兼顧成本與速度?
第二章|記憶體金字塔與 DRAM 飢荒
這時,我們就必須重新審視這間供 AI 工作的「圖書館」了。
在這個空間裡,原本存在著多種不同級別的儲存位置:

譯者的手邊(HBM,高頻寬記憶體):
這是 AI 手上正攤開、正在閱讀的那一頁。它的速度極快,但容量小得可憐,而且價格十分昂貴。
面前的書桌(DRAM,動態隨機存取記憶體):
這是 AI 面前的桌面。它的速度同樣很快,但依然放不下太多東西。
樓下的地下總書庫(NAND SSD / 網路共享儲存):
這裡的空間海量、價格便宜,但要把書從樓下調上來,得花費比較多的時間。
既然越近越好,最直覺的解決辦法就是多買一些最頂層的記憶體。
如果把 HBM 堆滿,把 DRAM 加到極限,讓 AI 的書桌大到用不完,問題不就解決了?
道理沒錯,但這條路被一件極其現實的事堵死了,那就是 HBM 和 DRAM 的價格與產能限制。
隨著 AI 運算規模爆發,AI 晶片極度依賴最頂端的 HBM。然而,HBM 的製造工藝極其複雜,需要將多層 DRAM 晶粒垂直堆疊,這消耗了大量的全球晶圓產能。
生產每一 GB 的 HBM,大約會消耗掉傳統 DDR5 記憶體三倍的晶圓產能。
這導致了嚴重的連鎖反應:晶片大廠將產能大量轉向利潤更高的 HBM,進而抽乾了標準 DRAM 的產能,引發了結構性的記憶體短缺與價格儲存成本飆漲。
面對這個「高速記憶體又貴又缺,但 AI 資料量卻越來越大」的殘酷現實,科技巨頭們開始尋找新的出路:
如何讓便宜、容量大但速度慢的 SSD(快閃記憶體),去扮演高昂 DRAM 的角色?
這不再只是單一廠商的嘗試,而是整個晶片產業的共識。
2.1 AMD 與 NVIDIA 的新解法

例如,AMD 在 2026 年 6 月收購了記憶體優化新創公司 MEXT。
MEXT 的核心技術就是利用 AI 演算法,精確預測哪些資料即將被使用,並提前將資料從便宜的 SSD 搬移到 DRAM 中。
而在2026年年初,NVIDIA 提出了記憶體分層架構(CMX(Context Memory Storage,脈絡記憶體儲存)平台)。
NVIDIA 決定在「書桌(DRAM)」與「地下書庫(傳統硬碟)」之間,硬是蓋了一個「專屬的小書架」,也就是名為「G3.5」的脈絡記憶體層。
這個 G3.5 樓層的核心就是 CMX 平台。它是一個由高速快閃記憶體組成的硬體陣列,並透過以下幾位「圖書館管理員」的通力合作,實現了極高效率的運作。
2.2 CMX 平台的四大關鍵角色

軟體指揮官(NVIDIA Dynamo 與 NIXL):
這套推理框架與傳輸函式庫扮演了「有預知能力的調度員」。它們會預判 AI 接下來要講什麼話,在 AI 還沒開始處理之前,就提前把需要的短期記憶從 CMX 小書架(G3.5)搬回書桌(G2)或 AI 手上(G1)。
硬體快遞員(BlueField-4 DPU):
這顆專用的資料處理器負責管理所有的傳輸交通。它能以極高效率處理網路與硬碟協定,讓資料傳輸走專用綠色通道,完全不佔用主機 CPU 的運算資源。
空間規劃師(NVIDIA Grove):
當多個 AI 任務在不同電腦之間切換時,它會確保工作被分配到離資料最近的機櫃,讓 AI 可以秒速套用之前的記憶,不需要重新搬運。
高速氣送管(Spectrum-X 乙太網路):
這項網路技術負責將運算晶片與 CMX 儲存節點緊密連結,提供極低的延遲與超高頻寬,讓這個由快閃記憶體組成的共享書架,能像本地記憶體一樣快速反應。
2.3 CMX 實現的三大根本改變

在 CMX 平台加入後,NVIDIA 實際上實現了一套高效的「記憶體分層(Memory Tiering)」機制,徹底解放了最昂貴的硬體資源:
HBM(G1 核心層)得到了解放:
現在,HBM 不需要再硬塞幾百 GB 的對話小抄,它只保留最核心的 AI 模型本身,以及當下正在處理的那個字的 KV 快取。
這讓 GPU 可以專心釋放算力,跑出極致的運算速度。
CMX(G3.5 延伸層)承接海量記憶:
那些前幾分鐘聊過、等一下可能還會用到的海量 KV 快取,會被分流到由超高速 NVMe SSD 組成的 CMX 平台上。
在整個機櫃(Pod)的規模下,CMX 能為 GPU 提供太位元組(TB)級別的共享空間。
無感知的預載機制(Prestage):
當 AI 準備回答下一句話時,BlueField-4 DPU 與 Dynamo 軟體會提早一步,將等一下要用的小抄從 CMX 預先載入到 HBM 中。
由於 Spectrum-X 網路搭配了 RDMA(遠端直接記憶體存取)技術,整個傳輸過程完全不需要驚動主機 CPU 進行審核,速度幾乎與本地 DRAM 一樣快,徹底消除了 GPU 坐在那裡發呆等待資料的閒置時間。
2.4 智慧夾層的共享優勢
回到圖書館的比喻,NVIDIA 沒有去擴大譯者手上的工作紙張,也沒有更動樓下那間慢吞吞的中央書庫。
他們在兩者之間蓋了一個「智慧夾層」(G3.5),並配備了一條專屬的氣送管(Spectrum-X 網路)與一位極其敏捷的專職助手(BlueField-4 DPU)。
當 GPU 寫完一部分草稿後,助手會立刻將這些草稿收進夾層中。當 GPU 需要引用前文時,助手能搶在 GPU 開口前,將草稿透過氣送管精確地送回桌上。
最關鍵的是,這個夾層是共享的。整棟大樓裡的所有 AI 都可以隨時調閱彼此存放在夾層中的脈絡資料。
如果 GPU A 累了,GPU B 接手時,能立刻從夾層中調出先前的草稿繼續工作,完全不需要重新詢問讀者問題,也不需要每個人都跑回地下總書庫重新調閱。
第三章|NAND 為什麼非要控制器不可?
所以我們知道了,現在業界的方向是將 SSD 扮演 DRAM。
但在過去一年的記憶體狂潮中,其實還是有很多投資者仍然在問:
「SSD(固態硬碟)跟 NAND Flash(快閃記憶體)到底有什麼不同?它們跟 DRAM 又差在哪裡?」
要搞懂這點,我們得先釐清一個最基本的關係:
NAND Flash 是「麵粉」(原料): 它是一種半導體晶片,負責儲存資料,但它天生有缺陷,無法直接拿來用。
SSD 是「麵包」(成品): 它是把 NAND Flash 晶片,加上「控制器大腦」與電路板組裝在一起後,可以直接插在電腦上使用的完整硬碟。
搞懂了這個關係,我們再來拆開「DRAM」與「NAND Flash」這兩大晶片陣營,在物理本質、身價以及技術難度上的巨大鴻溝。
3.1 DRAM 與 NAND:平房 vs 摩天大樓的成本鴻溝

在半導體的世界裡,DRAM(動態隨機存取記憶體,包括 HBM)與 NAND Flash(快閃記憶體)是兩條完全不同的演化支線。
它們最本質的差異,可以用一個極其簡單的物理規律來解釋:一個只能蓋平房,另一個卻能蓋摩天大樓。
DRAM 追求的是極致的速度。
為什麼貴? DRAM 的結構是利用微小的「電容器」來儲存電荷。因為要跟 CPU/GPU 進行奈秒級的極速對話,它的製造工藝要求極高,就像在晶片上鋪設完美的磁浮軌道。
主要的限制: 這種高精度的電容器結構極難往上堆疊。這意味著 DRAM 在晶片上只能蓋「平房」。既然地皮(晶圓面積)有限,你又不能往上蓋,想要更多容量就只能買更多地皮,這導致 DRAM 的每單位容量成本極其昂貴。
NAND 追求的是極致的容量與低成本。
為什麼便宜? NAND 的物理結構允許科學家像蓋摩天大樓一樣,把儲存單元一層一層「垂直堆疊」上去(這就是 3D NAND)。
主要的好處: 如今的 NAND 技術已經可以輕鬆疊到 200 層、甚至 300 層以上。
在同樣大小的地皮(晶圓面積)上,DRAM 只能蓋 1 層平房,NAND 卻能蓋 300 層大樓。
分攤下來,NAND 的每單位容量造價,自然便宜到只有 DRAM 的幾十分之一。
簡單來說:
DRAM 賣的是「速度與造路工藝」,因為只能蓋平房,所以容量小、身價極貴。
NAND 賣的是「空間與堆疊技術」,因為能蓋摩天大樓,所以容量超大、身價便宜。
這也決定了它們在電腦裡的命運:DRAM 負責在第一線陪著處理器瘋狂飆速,而 NAND 則在後方默默當個容量巨大的便宜倉庫。
3.2 裸 NAND 的三大問題
當 CPU 或 GPU 想要讀寫 DRAM 時,它們是直接「點名」的。
DRAM 的每一個儲存單元都有一個完美的、固定的物理地址,就像圖書館裡編號永遠不變的抽屜。
GPU 說要看第 100 號抽屜,DRAM 就能在幾奈秒內精準打開。DRAM 本身非常聽話、不掉資料、不會磨損,因此它不需要任何中間人,可以直接與處理器對話。
但 NAND 就完全是另一回事了。裸 NAND(Raw NAND)本身是一個脾氣極其暴躁、充滿物理缺陷的「問題兒童」:
它會磨損: 電子每次強行進出,都會對晶片結構造成微小的破壞。寫入次數多了,晶片就會「漏風」,這個區域就報廢了。
它不能直接覆寫: DRAM 可以隨意修改單一字元,但 NAND 不行。NAND 的讀寫是以「頁(Page)」為單位,但擦除卻必須以極大的「區塊(Block)」為單位。這就像你想修改筆記本上的一個錯字,卻必須把整頁用橡皮擦擦掉重寫一樣。
它隨時會寫錯(Bit Error): 隨著使用時間變長,電子會亂跑,導致原本寫入的 1 莫名其妙變成 0。
3.3 控制器與 FTL:把問題兒童包裝成穩定 SSD

為了解決這個問題,每一顆 SSD 內部,都必須配備一位「貼身管家」:控制器晶片(Controller),以及運行在裡面的靈魂軟體 FTL(Flash Translation Layer,快閃轉譯層)。
這個管家的工作,就是當一個「超級騙子兼翻譯官」。
當電腦想要寫入資料到「邏輯位址 A」時,管家不能直接寫在 A,它得在後台默默做以下幾件事:
平均抹寫(Wear Leveling): 算好每一塊黏土板被刻過幾次,刻意把新資料寫到比較少用的板子上,免得某些板子先被「刻穿」報廢。
垃圾回收(Garbage Collection): 趁電腦不注意時,把那些零碎、沒用的資料挑出來,集中搬移,騰出乾淨的整塊空間以便下次擦除。
錯誤修正(ECC): 隨時拿著放大鏡檢查字跡,發現有電子漏網、字跡模糊時,立刻用演算法把正確的字還原回來。
最後,管家再和電腦說:「報告主機,資料已經安全寫入 A 了!」
3.4 為什麼 DRAM 可以直連、NAND 卻需要保姆?
簡而言之,DRAM 可以直接與處理器對話;而 NAND 必須依賴「控制器晶片 + FTL 軟體」這個中間角色,才能被穩定且有效地使用。
這個「保姆」機制,讓原本問題重重的裸 NAND,變成了一種可靠、便宜且容量巨大的儲存解決方案。
它不只負責資料的正確讀寫,還要處理磨損、錯誤修正、以及邏輯位址與物理位址的轉換等複雜工作。
正因為控制器在 SSD 中扮演如此關鍵的角色,當我們希望 SSD 能夠承擔更多原本由 DRAM 負責的工作時,控制器的能力就成為決定成敗的重要因素。
第四章|從零售、雲端到 AI:儲存架構的演進
在深入探討 SSD 之前,我們必須先釐清一個最根本的疑問:為什麼過去的儲存架構不需要這麼複雜?
要理解這個改變,我們得把時間拉長,看看儲存架構在「消費級零售時代」、「傳統資料中心時代」以及當下的「AI 時代」經歷了怎樣的蛻變。
4.1 第一階段:消費級零售時代(單兵作戰與被動儲存)
Keep reading with a 7-day free trial
Subscribe to FOMO研究院電子報 to keep reading this post and get 7 days of free access to the full post archives.