
光通訊起飛,隨便買都會賺?LPO、CPO 與矽光子是甚麼? 深度分析第23期:MRVL, LITE, COHR, FN


我們往往以為,只要買了 10,000 顆最強的 GPU,把它們堆在機房裡,AI 模型就會自動變聰明。
但事實是,如果這些大腦之間無法順暢溝通,那麼這堆價值數十億美元的矽晶片,就只是一堆昂貴的擺設,形成了一座座「算力孤島」。
想像一下,你擁有全世界最聰明的 100 位科學家(GPU),但你把它們關在不同的房間裡,只允許他們用傳紙條(低速傳輸)的方式溝通。這項研究永遠不會完成。
AI 的本質,不僅僅是「計算」,更是「協作」。而協作的瓶頸,不在晶片內部,而在晶片之外。
隨著速度邁向 800G,網路設備本身佔資料中心總耗電的比例也將突破 20%。
這意味著,我們花大錢買來的電力,有越來越高的比例不是用來「計算」,而是消耗在了「搬運數據」的過程上。
因此,我們正處於一個歷史性的轉折點:資料中心正在從「電氣時代」艱難但必然地邁向「光子時代」。
為了徹底理解這場變革,我們將在接下來的章節中依序探討:
物理極限: 為什麼銅線快要撐不住了?(第 1-2 章)
硬體解構: 光收發模組(光模塊)內部的運作原理與關鍵玩家。(第 3-4 章)
技術演進: 從 LPO 到 CPO,未來的封裝技術之爭。(第 5-6 章)
市場版圖: Nvidia、Google 與乙太網路聯盟的三國演義,以及投資地圖。(第 7-9 章)
第一章:速度的量級——從看 Netflix 到訓練大腦
在我們討論銅線為什麼會燒掉,或者雷射為什麼這麼貴之前,我們必須先建立一個概念:我們到底在談論多快的速度?
新聞裡常提到的 400G、800G、1.6T,這些數字聽起來很抽象。讓我們用一個你熟悉的單位來換算。
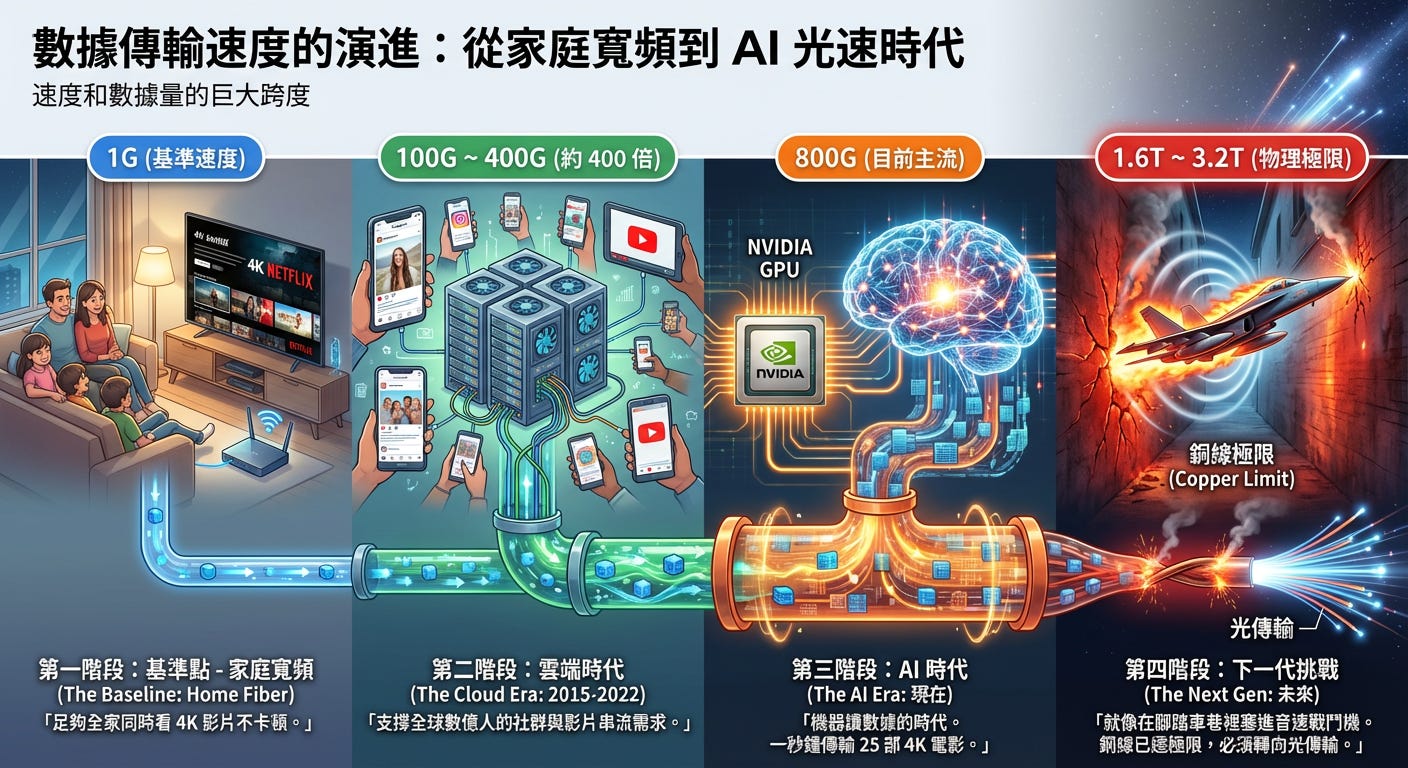
1. 基準點:你家的光纖寬頻 (1G)
現在一個家庭最快的網路通常是 1G (1 Gbps)。
概念: 這速度足夠讓你全家同時看 4K 的 Netflix 都不會卡頓。
能力: 下載一部兩小時的高畫質電影,大約需要 30-60 秒。
2. 雲端時代:100G ~ 400G
時間點: 2015 - 2022 年
場景: 當你在 Instagram 上滑動態,或者在 YouTube 看影片時,這些數據是從 Google 或 Meta 的資料中心傳出來的。
需求: 為了應付幾億人的影片串流需求,資料中心內部的伺服器開始使用 100G 到 400G 的光模組。
意義: 這已經很快了,相當於你家網速的 400 倍。這條「水管」足夠粗,讓人類享受了十年的移動互聯網黃金期。
3. AI 時代:800G
時間點: 現在
場景: ChatGPT 的誕生改變了一切。以前是「人看影片」,現在是「機器讀數據」。Nvidia H100 GPU 在訓練模型時,需要吞吐的數據量是驚人的。
需求: 400G 的水管瞬間爆滿。為了釋放 H100 的潛能,高階 AI 叢集開始大量採用 800G 的光模組。
能力: 800G 意味著什麼?意味著一秒鐘可以傳輸 25 部 4K 電影。
現狀: 這是目前市場的主流,也是為什麼旭創 (Innolight) 營收暴漲的原因。
4. 下一代:1.6T ~ 3.2T
時間點: 未來數年
場景: Nvidia 的 Blackwell 以及未來的 Rubin 架構。AI 模型從「文字」進化到「影片」(如 Sora),參數量從「兆」進化到「十兆」。
需求: 800G 也不夠用了。我們需要 1.6T (1600G) 甚至 3.2T。
物理上的極限意義: 1.6T 相當於你家網速的 1600 倍。想像一下,要在原本只能跑腳踏車的小巷子裡,硬塞進去一台以音速飛行的戰鬥機。
這就是問題的根源:
當速度只有 100G 時,銅線還能輕鬆應付。
當速度來到 800G 時,銅線開始發燙、喘氣。
當速度衝向 1.6T 時,銅線的有效傳輸距離被壓縮到極限(僅剩機櫃內部極短距離)。這就是為什麼我們需要光,以及為什麼我們需要接下來提到的那些昂貴技術。
第一章小結:
演進之路: 我們已從雲端時代(100G-400G)跨入 AI 時代(800G),現在正凝視著下一代標準(1.6T)。
1.6T 門檻: 當速度達到 1.6T 時,傳統銅線在物理上已無法在有效距離內傳輸訊號。
驅動力: Nvidia 的 Blackwell 架構及未來的晶片,所需的頻寬將是目前家用網路速度的 1600 倍以上。
第二章:物理學的鐵壁——為什麼銅線撐不住了?
理解了 1.6T 是多麼恐怖的速度後,你就能明白為什麼它的老搭擋——銅線(Copper)撐不住了。
在過去的幾十年裡,電腦內部和伺服器之間,主要靠銅線傳輸電子訊號。銅便宜、耐用、技術成熟。
但隨著 AI 時代的到來,數據傳輸速度飆升至 800G 甚至 1.6T,銅線撞上了一堵看不見的物理高牆。
1. 微觀視角:電子的擁擠效應(集膚效應)

在微觀物理世界裡,銅線有一個致命傷,叫做「集膚效應」(Skin Effect)。
當訊號頻率(速度)越來越快時,電子不再乖乖地走在銅線的中心,而是傾向於擠在銅線的「表面」流動。
你可以把這想像成一條寬敞的高速公路,但所有的車子都死命地擠在最外側的路肩上開,中間的車道全部空著。
結果就是:
電阻急劇升高: 通道變窄了,電子互相推擠。
訊號衰減: 訊號在銅線裡跑不到 1 公尺,波形就爛得像一團雜訊。
發熱: 為了把訊號硬推過去,你必須加大電壓,這導致銅線變成了一根發熱絲。
2. 第一道防線:主機板上的救星——Retimer 與 Astera Labs

在訊號衝出機殼之前,它首先得在主機板上存活下來。
隨著 PCIe 5.0 和即將到來的 6.0 時代,訊號在電路板上跑不到幾英吋就會衰減。這時候,我們需要第一種救兵。
這就是 Astera Labs (ALAB) 的主場。他們的旗艦產品 Retimer(重計時器) 就像是馬拉松比賽中的「中繼醫療站」。
當電子訊號在主機板上跑得氣喘吁吁、波形失真時,Retimer 會把它攔下來,進行數位修復(Re-time),把雜訊洗掉,重新生成一個乾淨強壯的訊號,再踢它一腳讓它繼續跑向 GPU 或 CPU。
ALAB 的護城河: 他們是 PCIe 和 CXL 協議 的絕對王者。只要你的伺服器內部需要 CPU 和 GPU 高速對話,你就繞不開 ALAB 的晶片。
但這只解決了「機殼內部」的問題。當訊號要離開伺服器,通過纜線連到交換機時,銅線面臨了更大的挑戰。
3. 銅線的反擊:ACC/AEC——被低估的過渡期金礦

以前,我們用便宜的「被動銅纜」(DAC)連接機櫃裡的設備。但在 800G/1.6T 的速度下,被動銅纜就像一根堵塞的水管,根本傳不動。
這時,產業界有兩個選擇:
換光纖: 性能完美,但價格昂貴,且功耗高。
讓銅線變聰明: 這就是 AEC (主動式電纜) 的誕生。
這裡有一個關鍵的技術區分,也是投資者容易搞混的地方:ACC vs. AEC。
ACC (Active Copper Cable): 這是「低配版」。它在線纜接頭裡裝了一個放大器(Redriver),就像拿大聲公喊話,聲音變大了,但雜訊也跟著變大了。它只能傳輸很短的距離。
AEC (Active Electrical Cable): 這是「高配版」,也是 Credo (CRDO) 的殺手鐧。
AEC 的原理,其實就是把 Retimer 晶片從主機板上搬到了「線纜的接頭裡」。
AEC 不只是放大訊號,它還具備 CDR (時鐘數據恢復) 功能。
這就像給銅線裝了一個「即時翻譯機」,它能消除抖動(Jitter),並透過前向糾錯(FEC)確保數據完整。
這讓銅線能做到以前只有光纖能做到的事:在更細、更軟的線材中,穩定傳輸 3 到 7 公尺。
為什麼是 Credo?

雖然 ALAB 也做 Retimer,但 Credo 是 Ethernet(乙太網路)AEC 市場的絕對霸主,市佔率超過8成。
ALAB 正在嘗試用 PCIe 規格的 AEC 線纜切入市場(主要用於機櫃內 GPU 互連)。
Credo 則已經壟斷了機櫃內「交換機到伺服器」的乙太網路連接。
投資意義:
在 CPO (光電共封裝) 技術於 2027 年全面進場之前,AEC 是未來 3 年的「過渡期金礦」。
微軟、亞馬遜、xAI 為了節省成本,在機櫃內部的短距離連接(<3公尺),會優先採用 Credo 的 AEC 方案,而不是昂貴的光纖。
4. 架構視角:Scale-Up 與光的最終接管

雖然 ACC/AEC 成功守住了「機櫃內部」這最後 2 公尺的防線,但物理學是無情的。當傳輸速度越來越快,大家都會希望能找到最後的最優解。
為什麼我們現在對「距離」這麼敏感?因為 Nvidia 改變了電腦的定義。
在傳統雲端時代,伺服器是獨立工作的。
但在 AI 時代,為了訓練像 GPT-4 這樣的大模型,單顆 GPU 的力量微不足道。Nvidia 的新架構(如 GB200 NVL72)做了一件瘋狂的事:它把 72 顆 GPU,透過極其密集的連接,偽裝成「一顆超級巨大的 GPU」。
這就是所謂的 Scale-Up(向上擴展)。
為了讓這 72 顆大腦感覺自己是一體的,它們之間的通訊延遲必須低到忽略不計。
機櫃內部(Intra-rack): 在這個狹窄的空間裡(約 1-2 公尺),Nvidia 目前還能用銅線(NVLink)勉強支撐,配合強大的背板技術,這是銅線最後的堡壘。
機櫃之間(Inter-rack): 一旦你要連接兩個機櫃,距離超過了 2 公尺,銅線就徹底宣告死亡。
這就是「光」登場的時刻。
光子沒有質量,不會像電子那樣互相排擠(沒有集膚效應),也不會發熱。光在玻璃纖維中飛行,幾乎沒有阻力。
第二章小結
趨膚效應 (Skin Effect): 隨著頻率升高,電子會擁擠在銅線表面,導致電阻增加、發熱與訊號衰減。
止痛藥: Retimer(時序重整晶片,如 Astera Labs)能延長銅線壽命,但代價是延遲與功耗。
銅的最後防線: 主動式電纜 (AEC/ACC) 將是未來 2-3 年內短距離(機櫃內)連接的主流方案。
第三章:光子的進擊地圖——從邊緣攻入核心
在我們深入研究具體的投資標的之前,我們必須先搞清楚現在的 AI 資料中心到底是怎麼連起來的。
要看懂這場戰爭,你只需要記住一個黃金定律:
「速度越快,銅線能跑的距離就越短。」
隨著 AI 要求的速度從 400G 飆升到 1.6T,銅線的勢力範圍正在急劇縮小,而光纖正在步步進逼,填補銅線留下的真空。
第一部分:戰線的推移(時間維度)
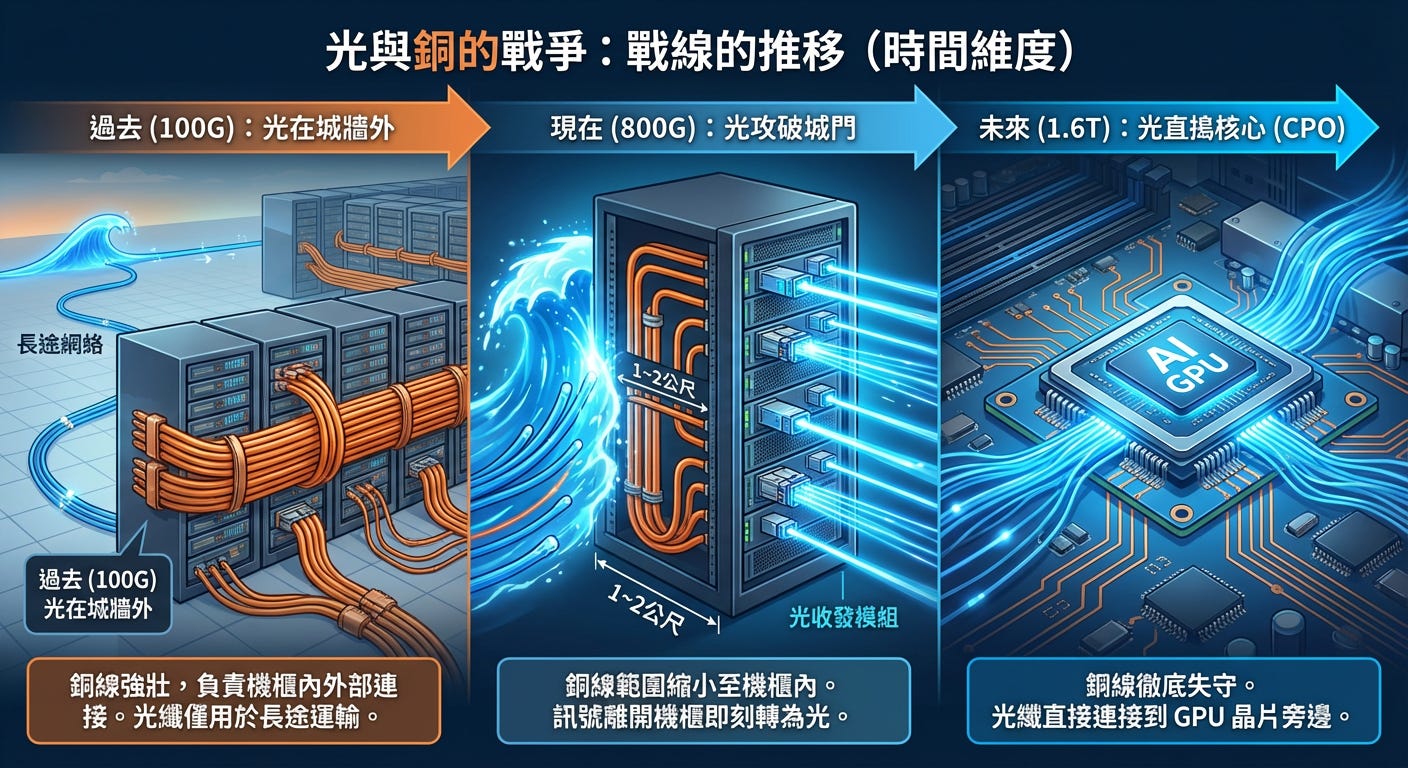
這場戰爭經歷了三個階段,光子就像不斷推進的浪潮,從外圍一步步殺進核心:
過去 (雲端時代):光在城牆外
速度 100G 時,銅線還很強壯。機櫃內部的連接,甚至機櫃與隔壁機櫃的連接,都可以用便宜的銅纜搞定。光纖只被用在長途運輸。現在 (AI 爆發期):光攻破城門
速度來到 800G,銅線的勢力範圍縮小到 1~2 公尺。只要訊號一離開機櫃,就必須立刻轉成光。這導致了光收發模組的需求量暴增。未來 (下一代 AI):光直搗核心
當速度來到 1.6T,銅線連機櫃內部都守不住了。光纖必須直接插到 GPU 晶片的旁邊(CPO 技術),因為電訊號連從晶片走到機殼面板這短短的距離都走不到了。
第二部分:目前的防線地圖(空間維度)
基於上述的演變,目前的 AI 資料中心呈現出一種「俄羅斯套娃」的結構。我們可以根據「距離」,將其劃分為四道防線:

第一層:晶片與晶片之間 (Chip-to-Chip) —— 銅線的最後堡壘
場景: 在同一個綠色電路板上,兩顆 GPU 緊緊挨在一起。
距離: 幾公分到十幾公分。
連接方式: 銅線 (Copper Trace)。
現狀: 這是銅線唯一還能稱王的地方。因為距離極短,電訊號還沒來得及衰減就到了。Nvidia 的 NVLink 目前主要就是在這個層級運作,讓幾顆 GPU 像連體嬰一樣共享記憶體。
第二層:伺服器內部 (Server/Intra-Rack) —— 銅與光的交界
場景: 在一個機櫃(Rack)裡,可能有 8 到 72 顆 GPU。它們需要連到機櫃頂端的交換機 (Top of Rack Switch)。
距離: 1 到 3 公尺。
連接方式: 銅纜 (DAC) 為主,光纖 (AOC) 為輔。
現狀: 這是目前競爭最激烈的戰場。Nvidia 的 NVL72 架構試圖用一種超粗的銅纜背板來解決問題。但隨著速度越來越快,銅纜變得像水管一樣粗且硬,安裝困難。光通訊正在這裡虎視眈眈,準備隨時接管。
第三層:機櫃與機櫃之間 (Rack-to-Rack) —— 光的絕對領域
場景: 你的 AI 模型太大,一個機櫃裝不下,需要把 100 個機櫃連起來。
距離: 5 公尺到 100 公尺。
連接方式: 光纖 (Optics)。
現狀: 這裡銅線已經徹底死亡。訊號一出機櫃,就必須變成光。這是目前光通訊產業最大的營收來源。
第四層:資料中心之間 (Data Center Interconnect) —— 長程光纖
場景: 連接台北和高雄的機房。
距離: 數公里到數百公里。
連接方式: 高功率光纖。
現狀: 這是電信等級的傳輸,完全依賴最高階的雷射技術。
關鍵結論:那個「銀色盒子」插在哪?

現在你知道地圖了。當訊號要從第二層(伺服器)衝向第三層(外部網路)時,它必須經過一個「關卡」。
在伺服器的背後,有一排插槽。你需要買一個長得像 USB 隨身碟的金屬裝置插進去。
這一頭,它接收伺服器送來的電子訊號。
那一頭,它連著光纖,射出雷射訊號。
這個負責在「電的世界」與「光的世界」之間進行翻譯與轉換的裝置,就是現在 AI 伺服器光傳輸的主角——光收發模組 (Optical Transceiver)。
接下來,讓我們像外科醫生一樣,解剖這個不起眼但價值連城的銀色盒子。
第三章小結:
黃金法則: 速度越快,銅線能跑的距離越短。光學元件正被迫離晶片越來越近。
「俄羅斯娃娃」結構:
晶片對晶片: 銅線仍是王者 (NVLink)。
機櫃內: 銅線 (DAC/AEC) 與光纖的戰場。
機櫃對機櫃: 必須使用光纖。
硬體核心: 光收發模組(那個「銀色盒子」)是目前電訊號 GPU 與光網路之間的翻譯官。
第四章:銀色盒子的解剖學——供應鏈的權力結構

如果說 Nvidia 的 GPU 是現代 AI 的大腦,那麼插在伺服器背後、那一個個不起眼的「銀色盒子」(光收發模組,Optical Transceiver),就是它的聲帶與耳朵。
沒有這些盒子,H100 晶片就是一個被鎖在黑屋子裡的天才,無法與外界溝通。
這個小東西,內部其實是一座微型的精密工廠,其複雜程度甚至不亞於一支智慧型手機。
在這個盒子裡,藏著光通訊產業最殘酷的利潤分配邏輯與護城河。讓我們像外科醫生一樣,把它切開來看看。
第一層:大腦(DSP)——翻譯官的過路費

當 GPU 發出訊號時,它是「數位」的(0 和 1)。但光纖裡傳輸的光,本質上是「類比」的波動(波峰與波谷)。
這兩者語言不通。如果直接把 GPU 的訊號打出去,在 800G 的超高速下,訊號會變成一團亂碼。
這時,我們需要一個絕頂聰明的翻譯官,這就是 DSP(數位訊號處理器)。
雙寡頭的壟斷:Marvell 與 Broadcom
這個翻譯官的工作極其困難,它必須在奈秒級的時間內,用複雜的數學演算法修復爛掉的訊號。這需要最先進的製程(如台積電 5nm/3nm)。
在這個領域,全球只有兩位真正的霸主:
Marvell (MRVL): 光學 DSP 的專科醫生。他們在 PAM4 技術(一種高效率訊號編碼)上佈局極早,目前在 AI 光模組市場中,Marvell 的 DSP 被視為首選。

Broadcom (AVGO): 網路帝國的皇帝。他們不僅做 DSP,還做交換機晶片(Tomahawk)。他們的策略是「全家桶」——如果你買我的交換機晶片,最好也用我的 DSP。

投資洞察:
這是一個「收過路費」的生意。無論下游是誰組裝這個盒子,無論最後賣給 Google 還是 Meta,只要是高速模組,幾乎都要向這兩家公司繳納昂貴的「技術溢價」。它們擁有最高的毛利(60-70%)和最深的護城河。
第二層:心臟(Laser)——矽無法發光的救贖
翻譯官(DSP)整理好訊號後,需要有人把它「喊」出去。這就是雷射(Laser)的工作。這也是整個供應鏈中,物理壁壘最高的地方。
1. 為什麼我們需要做雷射的公司?(物理學的鐵律)

你也許會問:「台積電既然能做出全世界最強的晶片,為什麼不能順便把發光的雷射也做進去?」
答案是:材料不對。
目前的晶片主要是用「矽 (Silicon)」做的。矽是一個很棒的材料,便宜又好用,但它有一個致命缺陷——它是「啞巴」。
矽原子結構決定了它只能導電,不能發光(它是間接能隙材料)。如果你通電給矽,它只會發熱,不會發光。
要產生雷射,必須使用一種稀有且昂貴的材料——磷化銦 (InP, Indium Phosphide)。

這種材料被稱為「化合物半導體」。如果說矽是蓋房子用的磚頭,那磷化銦就是昂貴的水晶。它脆弱、難以加工,但它天生就能發出純淨的光。
Lumentum (LITE) / Coherent (COHR) 就是全球最擅長駕馭這種「水晶」的工匠之一。
他們在晶圓廠裡生長出磷化銦晶體,並將其切割成微小的雷射晶片。這不是台積電的賽道,這是 Lumentum 的絕對領域。
2. 技術解密:為什麼 AI 需要特殊的雷射?
普通的雷射(比如你家滑鼠裡的)是「直接調變」(DML)。原理很簡單:開燈代表 1,關燈代表 0。
但在 AI 的 800G 高速傳輸下,傳統方法在長距離或高效能場景面臨挑戰。因為燈泡直接開關的速度是有極限的,閃太快,燈泡會壞,光也會變形。
於是,這些公司採用了一種高階技術——EML (電吸收調變雷射)。
原理: 雷射燈泡永遠保持常亮(提供穩定的光流)。
動作: 在燈泡前面加一個極其快速的「快門」(調變器)。透過快速開關快門來切分光線,產生 0 和 1。
優勢: 光源極度純淨,傳輸距離遠,速度極快。
在這裡,我們看到了兩種截然不同的生存之道:
專精的軍火商:Lumentum (LITE)
Keep reading with a 7-day free trial
Subscribe to FOMO研究院電子報 to keep reading this post and get 7 days of free access to the full post archives.