
Gemini如何強勢反擊?TPU能搶佔GPU市場?博通起了甚麼作用?深度分析第22期:GOOG, AVGO, NVDA


在科技界的歷史長河中,「創新者的窘境」(Innovator’s Dilemma)是所有巨頭揮之不去的夢魘。
柯達發明了數位相機卻被其埋葬,諾基亞擁有智能手機技術卻不敢推向市場。
2022 年末,當 OpenAI推出了 ChatGPT,矽谷陷入觀望與焦慮。華爾街開始質疑這家靠搜尋廣告躺著賺錢的巨人,是否將會成為AI時代的輸家。
然而,三年過去了,Google 並沒有成為下一個柯達。
但這場反擊戰的真相,並不僅僅發生在我們看得到的螢幕上(Gemini vs. GPT),更發生在我們看不見的數據中心深處。
這是一場關於算力主權、晶片架構(TPU vs. GPU)以及供應鏈博弈的深層戰爭。
從山景城的「紅色代碼」到與 Broadcom 的結盟,從被 Nvidia 扼住咽喉到建立自研晶片的護城河,從AI的輸家到現在大有一統江山之勢,Google 正在進行一場科技史上最昂貴、最激進的「換心手術」。
我將會用這篇深度報告,為大家拆解 Google 在 AI 時代的完整戰略版圖,您將了解到:
危機與轉機:Google 如何克服內部的官僚主義,將 DeepMind 與 Google Brain 合併,並從「紅色代碼」的恐慌中催生出 Gemini 3.0。
技術的逆襲:Gemini 3.0 究竟憑什麼完勝對手?深入解析其背後的「經典擴展」策略、MoE 架構以及深度思考(Deep Think)能力。
隱形護城河:為什麼 TPU才是 Google 真正的底牌?深入解析 TPU 如何在成本和效率上,成為 Google 的「印鈔機」,以及TPU的隱憂。
幕後軍火商:揭秘 Broadcom(博通) 在這場戰爭中的關鍵角色。這對「軟硬體共生」關係如何運作?
雙面賽局:為何Google仍然要買入Nvidia GPU?背後有甚麼商業考量?
終局之戰:ASIC(自研晶片)最終會取代Nvidia 嗎?我們將通過分析,預判 AI 晶片市場從「獨裁」走向「劃江而治」的未來格局。
投資價值重估:深度剖析 Google 目前面臨的「薛丁格」投資屬性。
第一章:巨人甦醒前的惡夢——從「紅色代碼」到信任危機
在科技產業的興衰週期中,沒有什麼比「創新者的窘境」(Innovator’s Dilemma)更令人恐懼。
而在 2022 年末至 2025 年初,Google——這家曾經發明了 Transformer 架構(現代 AI 的基石)的巨人,似乎正一步步走向同樣的深淵。
ChatGPT 的 “T”
: A Journey from Transformers to GPT-4 and Beyond | by Mohdjasil | Medium")
故事的轉折點發生在 2022 年 11 月。當 OpenAI 發布 ChatGPT 時,Google 總部山景城(Mountain View)內的氣氛瞬間凝固。
這不僅僅是一個新產品的發布,這是一場對 Google 護城河的直接突襲。
最諷刺的是:OpenAI 用來顛覆 Google 的武器,其核心設計圖完全來自 Google。
很多人可能不知道,ChatGPT 這個名字中的 “T”,指的正是 Transformer。
這要回溯到 2017 年,Google 的研究團隊發表了一篇名為《Attention Is All You Need》(你只需要注意力機制)的論文。這篇論文在當時並未引起大眾轟動,但在 AI 學術界卻引發了核爆。

在此之前,AI 閱讀文章就像是一個「死記硬背的小學生」(RNN/LSTM 架構):它必須一個字一個字地讀,讀到句子結尾時,往往已經忘了開頭是什麼。
這導致舊時代的 AI 很難理解長文章或複雜的語意。
Transformer 架構改變了一切。
類比:上帝視角
想像你在讀一本書。
舊的 AI (RNN):像是拿著一根吸管在看書,視野只有吸管那樣大,一次只能看到一個字,讀起來既慢又容易斷章取義。
Transformer:像是開啟了「上帝視角」。它能同時(Parallel)看到整頁的文字,並且擁有一種叫「自注意力機制 (Self-Attention)」的超能力。它能瞬間畫出文字間的關聯線——當它看到「銀行」這個詞時,它會同時關注上下文是「河流」還是「金錢」,從而瞬間理解這是「河岸」還是「金融機構」。
Google 發明了這個「上帝視角」,並秉持著學術開放的精神,將其開源公諸於世。
他們以為這是在推動科學進步,卻沒想到,一家名為 OpenAI 的實驗室撿起了這份設計圖,並將其發揮到了極致。
被偷走的聖火

多年來,Google 內部的 LaMDA 模型在技術上並不遜色,但 Google 遲遲不敢發布。原因很簡單:聲譽風險與商業模式的衝突。
對於一家靠搜尋廣告賺取數千億美元的公司來說,一個會胡說八道的 AI 聊天機器人是巨大的風險;但對於一無所有的 OpenAI 來說,那是顛覆世界的武器。
當 ChatGPT 像病毒一樣席捲全球,Google 管理層隨即拉響了著名的「紅色代碼」(Code Red),代表了Google出現了生存危機。

如果用戶不再「搜尋」藍色連結,而是直接「詢問」AI 獲取答案,Google 的廣告帝國將在一夜之間崩塌。
創始人 Larry Page 和 Sergey Brin 被緊急召回,這在公司內部極為罕見。這兩位已經半退休的傳奇人物重回會議室,只為了一個目標:
喚醒這隻沉睡且自滿的巨人,在它被自己發明的技術殺死之前。
慌亂中的反擊與千億美元的代價

Google 的初步反擊是倉促且混亂的。2023 年初,為了回應 ChatGPT,Google 匆忙推出了 Bard。
然而,在首次公開演示中,Bard 錯誤地聲稱韋伯太空望遠鏡(JWST)拍攝了第一張太陽系外行星的照片(事實上是由歐洲南方天文台拍攝的)。
這個事實錯誤在天文學家眼裡或許只是小瑕疵,但在華爾街眼裡卻是致命的信號。
市場不需要一個完美的百科全書,但市場不能容忍 Google 在其最擅長的「資訊準確性」上輸給對手。
僅僅這一個錯誤,導致 Alphabet 股價單日暴跌接近10%,市值瞬間蒸發 1,000 億美元。
2024-2025:至暗時刻
如果說 Bard 的失誤是前奏,那麼 2024 年到 2025 年初則是 Google 的至暗時刻。投資者的焦慮並非空穴來風,數據支撐了恐慌:

搜尋帝國的裂痕:自 2015 年以來,Google 的搜尋市佔率一直穩居 90% 以上。但在 2024 年底,這一防線失守了。10 月份市佔率跌跛90%,隨後幾個月持續低迷。Perplexity 和 ChatGPT Search 等「答案引擎」正在改變用戶習慣——人們不想再點擊十個藍色連結,他們只想要答案。
產品信任崩塌:Google 試圖用 Gemini 奪回失地,卻再次跌跤。2024 年 2 月,Gemini 的圖像生成功能爆發了嚴重的「覺醒文化」(Woke AI)醜聞——它拒絕生成白人歷史人物的圖像,甚至生成了納粹裝束的有色人種士兵。這不僅是技術調整過度的問題,更讓開發者和企業用戶質疑:Google 的 AI 是否可控?是否中立?
蘋果的背刺傳聞:2025 年 5 月,市場傳出 Apple 考慮在 Safari 中取代 Google 作為默認 AI 搜尋引擎。這直接威脅到 Google 每年約 200 億美元的流量入口,導致股價再次重挫 。
當時的華爾街分析師們悲觀地認為,Google 陷入了一個「第 22 條軍規」(Catch-22):
如果不全力推廣 AI,會被 OpenAI 取代;如果全力推廣 AI,昂貴的算力成本和不再點擊廣告的用戶,將會摧毀自己最賺錢的搜尋業務。
巨人似乎被困在了自己的黃金籠子裡。
本章重點摘要 (Key Takeaways):
創新者的窘境: Google 發明了 Transformer 架構,卻因擔憂破壞高利潤的廣告商業模式,將先機拱手讓給 OpenAI。
信任崩塌: Bard 的演示失誤與 Gemini 的圖像生成爭議,導致 Google 市值蒸發千億美元,並動搖了市場對其技術可靠性的信心。
護城河鬆動: 搜尋市佔率跌破 90% 心理關卡,面臨 ChatGPT Search 與 Perplexity 等「答案引擎」對流量入口的直接掠奪。
在進入第二章之前,會員們可以投下你們的神聖一票,決定下星期「深入研究」的主題。
投票將在 3天後 結束。
第二章:帝國的反擊——Gemini 的誕生與 Google DeepMind 的整合
面對內憂外患,Google 做出了其歷史上最重要的一次組織架構調整。
結束內戰:Google DeepMind 的誕生
長期以來,Google 內部存在兩個頂級 AI 實驗室:Google Brain(由 Jeff Dean 領導,Transformer 的發源地)和 DeepMind(由 Demis Hassabis 領導,AlphaGo 的締造者)。這兩個部門雖然同屬 Google,但在文化和資源上長期處於競爭甚至對立狀態。
為了對抗 OpenAI,Google 必須結束這場內戰。2023 年,Google 宣布將兩者合併為 Google DeepMind。這是一個強制的聯姻,目的是集中所有的算力(TPU)和最聰明的大腦,共同打造一個能終結比賽的模型——Gemini。
從追趕到超越:Gemini 3 的逆襲
早期的 Gemini 版本(1.0 和 1.5)雖然縮小了與 GPT-4 的差距,但始終處於「追趕者」的角色。直到 2025 年 11 月,隨著 Gemini 3 Pro 的發布,戰局發生了根本性的逆轉。
這一次,Google 沒有再犯錯。
1. 硬實力的碾壓:在 GPT-5 的陰影下突圍
2025 年 8 月發布的 GPT-5.1 雖然強大,但被市場普遍認為「缺乏革命性」,它更像是一個平衡的通用工具,而非科學怪傑。
這給了 Google 絕佳的機會。
Gemini 3 Pro 發布當天即登頂 LMArena 排行榜(Elo 分數突破 1501),在「純推理」領域將 GPT-5.1 遠遠甩在身後:

人類終極考試(Humanity’s Last Exam):這是公認最難作弊的基準測試。Gemini 3 取得了 37.5% 的驚人分數(開啟深度思考後達 41%),而 GPT-5.1 僅為 26.5%。這 11% 的差距在 AI 領域如同鴻溝。
數學推理(MathArena Apex):Gemini 3 展現了統治力,得分 23.4%,相比之下 GPT-5.1 僅能處理基礎邏輯。
破除迷信:為什麼矽谷曾認為「擴展定律」已死?

在 Gemini 3 發布前夕,矽谷瀰漫著一股悲觀情緒。許多研究者認為 Scaling Laws(擴展定律) 已經撞上了天花板。
理由似乎很充分:
數據枯竭:高質量的互聯網文本快被餵光了。
邊際效應遞減:過去增加 10 倍算力能讓智商翻倍,現在似乎只能提升 10%。
不可持續的成本:訓練成本呈指數級上升,但模型變聰明的速度卻在變慢。
市場普遍認為,單純靠「堆料」的時代結束了,必須尋找全新的架構魔法。然而,Google DeepMind 的工程師們看著內部數據,得出了一個截然不同的結論:
牆並不存在,只是你們的梯子不夠長,或者爬梯子的姿勢不對。
2. 硬實力的碾壓:經典擴展(Classical Scaling)的復活
Gemini 3 的核心哲學是對 「經典擴展(Classical Scaling)」 的極致執行。
什麼是經典擴展?
簡單來說,就是在不改變基礎 Transformer 架構的前提下,通過增加基礎資源(數據集大小、算力、參數數量、上下文窗口),來換取性能的對數級增長。
Google 證明了只要解決了瓶頸(如數據質量和並行效率),模型能力依然能隨著資源投入而線性提升。
3.行業標準的極致化:MoE 與深度推理
在純文本和邏輯推理領域,Gemini 3 其實並沒有發明新魔法,而是將行業標準推向了物理極限。
Gemini 3 在三個關鍵維度上擊敗了 GPT-5:
第一招:混合專家架構(MoE)的巔峰
")
與 GPT-5 和 Llama 4 一樣,Gemini 3 也採用了 MoE 架構。它擁有超過 1 兆(Trillion) 個參數,但在處理每個查詢時,僅激活其中的 150-200 億 個參數。這並非 Google 獨有,但 Google 利用其TPU算力規模將其推向了極致。
什麼是混合專家模型 (MoE)?
想像一家擁有一萬名醫生的超級綜合醫院。
舊時代的「稠密模型」(Dense Model):就像是一個全科醫生,不管你來看什麼病,他都要調動大腦裡所有的醫學知識(從眼科到骨科)過一遍。這既慢又累,而且很難樣樣精通。
MoE 架構:這家醫院有一個聰明的「導診台」(Router)。當你進來時,導診台會判斷你是「骨折」還是「感冒」,然後只把你分配給對應的那 2-3 位專家。
優勢:醫院整體規模雖大(參數量大,知識淵博),但處理每個病人時只動用極少資源(推理成本低,速度快)。Gemini 3 就是這樣一座擁有頂級專家的超級醫院。
第二招:推理能力:Deep Think 與 100 萬 Token 的護城河
100 萬 Token 上下文(Context Window):
GPT-5:依然徘徊在 128k 到 256k Token。
Gemini 3:起步即 100 萬(1M)Token。這不僅是記憶力的差別,這是 「代理(Agentic)」 能力的質變。Gemini 可以一次性「讀」完整個項目的代碼庫或幾十本法律卷宗,並進行跨文檔推理。這讓它在真實工作場景(如審計、代碼重構)中擁有對手無法企及的「上帝視角」。
同時,Gemini 3 引入了類似 OpenAI o3 的「深度思考」模式。在面對複雜數學題(MathArena Apex 得分 23.4%)或代碼任務時,模型不會急著回答,而是先進入「內部沙盤推演」。
什麼是深度思考 (Deep Think)?

諾貝爾獎得主丹尼爾·卡尼曼將人類思維分為「系統 1(快思考)」和「系統 2(慢思考)」。
快思考 (System 1):就像有人問你「2+2 等於幾?」,你脫口而出「4」。這是直覺,也是大多數早期 AI(如 GPT-3.5)的工作方式——基於概率的「文字接龍」。
慢思考 (System 2):就像有人問你「234 乘以 956 等於幾?」。你無法脫口而出,你必須拿出一張草稿紙,列出算式,一步步計算,甚至回頭檢查有沒有算錯。
Gemini 的進化:Deep Think 模式就是給了 AI 這張「隱形的草稿紙」。在給你答案前,它已經在內部進行了多輪推理和自我糾錯。這讓它在數學和編程上的準確率有了質的飛躍。
第三招:原生多模態(Native Multimodal)
大多數競爭對手在處理視覺信息時,本質上仍是「拼湊」(Stitched)架構。而 Gemini 3 採用了單一統一 Transformer 堆疊。
為了理解這種差異的巨大影響,我們必須回到感知的本質。
什麼是多模態 (Multimodal)?

人類是天生的多模態生物。當你和朋友聊天時,你同時在做三件事:聽他的聲音(音頻)、看他的表情(視覺)、理解他的話語(文本)。這三種信息在大腦中是無縫融合的。
舊時代的「拼湊」AI (如早期的 GPT-4V):它本質上是一個純文字大腦。為了讓它「看圖」,工程師需要外掛一個視覺識別器,把圖片轉化成文字描述(例如:「圖片中有一直貓坐在沙發上」),再餵給大腦。這就像是「盲人聽廣播」——中間隔了一層翻譯,丟失了大量細節(如光影、微表情、氛圍)。
Gemini 的「原生」AI (Native Multimodal):它從出生那一刻起,就是在影片、圖片、聲音和文字的混合數據中訓練長大的。它不需要翻譯。它看到圖片就像人類一樣,是直接感知的。
戰場表現:這種架構優勢在 Video-MMMU(視頻理解) 上展現得淋漓盡致,準確率達到 87.6%。Gemini 3 能理解視頻中的因果關係、物理規律甚至情感氛圍,而對手只能做到識別物體。
Google 終於證明:Transformer 的發明者,回來了。
戰略轉向:從「實驗品」到「生產力」
Google 吸取了之前的教訓,Gemini 3 的發布策略極為激進:

直接植入搜尋引擎:Google 不再猶豫是否會蠶食廣告收入,直接在 Search 中部署 Gemini 3 的 AI 模式。這向市場傳遞了一個強烈信號:我們的模型成本已經低到可以大規模商用,且速度快到可以處理數十億次查詢。

操作型 AI(Operational AI):Google 不再將 Gemini 定位為「陪你聊天的助手」,而是定位為「幫你工作的代理(Agent)」。利用 Google Workspace 的生態優勢,Gemini 3 可以自動抓取 Gmail 的收據、對照日曆行程、並在 Sheets 中生成財務報表。這直接切中了微軟 Copilot 的腹地,讓企業用戶重新評估切換成本。

2025 年底,隨著 Gemini 3 的成功落地和 Google Cloud 利潤的飆升,華爾街的敘事徹底改變了。投資者意識到,之前的擔憂雖然合理,但低估了 Google 的底蘊。
霸權的幻覺——為什麼軟體沒有護城河?
不過,當華爾街為 Gemini 3.0 的跑分歡呼,慶祝 Google 重回王座時,資深的矽谷工程師們卻保持著一份冷靜。
因為他們深知 AI 行業的一個殘酷定律:在軟體架構的世界裡,沒有秘密。
Gemini 3.0 的勝利是真實的,但它也是極度脆弱的。
六個月的魔咒:透明的創新
Gemini 3.0 引以為傲的「稀疏混合專家模型(Sparse MoE)」、「深度思考(Deep Think)」以及「原生多模態」,雖然強大,但並非 Google 獨有的黑科技。
OpenAI 和 Anthropic 的頂級研究員只要看一下 Gemini 的技術報告,可能就可以在幾個月內反推出其背後的原理。
歷史數據無情地揭示了這場「蛙跳遊戲(Leapfrog Game)」的本質——領先優勢通常只能維持 6 到 9 個月:
 ( 202303) GPT-4 () (202406) Claude 35 Sonnet () (202508) GPT-51 () ( 202511) Gemini 30 ( MoE Deep Think) Gemini 30 ( 2026) ( 202605) GPT-6 Claude 5 _image_1")
2023.03:GPT-4 震驚世界(獨霸)。
2024.06:Claude 3.5 Sonnet 在編程領域反超。
2025.08:GPT-5.1 發布,雖無驚喜但穩住了基本盤。
2025.11:Gemini 3.0 在推理上領先。
這意味著,OpenAI ,Anthropic,Grok等的下一代模型很可能已經在訓練中,並準備在半年後再次刷新紀錄。
依靠算法取得的優勢,就像沙灘上的城堡,漲潮時就會消失。
本章重點摘要 (Key Takeaways):
組織重組: Google 克服官僚主義,強勢合併 Brain 與 DeepMind,集中算力資源與頂尖人才,結束了內部的路線之爭。
技術逆襲: Gemini 3.0 憑藉「經典擴展」策略與 MoE 架構,在推理與數學領域超越 GPT-5.1,並利用 100 萬 Token 上下文建立差異化優勢。
原生多模態: 不同於對手的「拼湊」架構,Gemini 具備原生理解視聽資訊的能力,在影片理解等領域展現統治力。
軟體的脆弱性: 儘管目前領先,但軟體算法容易被逆向工程,單純依靠模型性能的領先優勢通常僅能維持 6-9 個月。
第三章:矽谷的地下堡壘——TPU 的十年長征
既然軟體容易被複製,那麼 Google 真正的護城河在哪裡?答案在於「垂直整合的反饋迴圈」。
真正讓Gemini與眾不同的,是其獨家的TPU。
Gemini是世界上第一個完全不依賴 NVIDIA GPU,而是全流程在 Google 自研晶片 TPU(張量處理單元)上訓練和推理的前沿模型。
這為 Google 帶來了四個競爭對手無法複製的優勢:
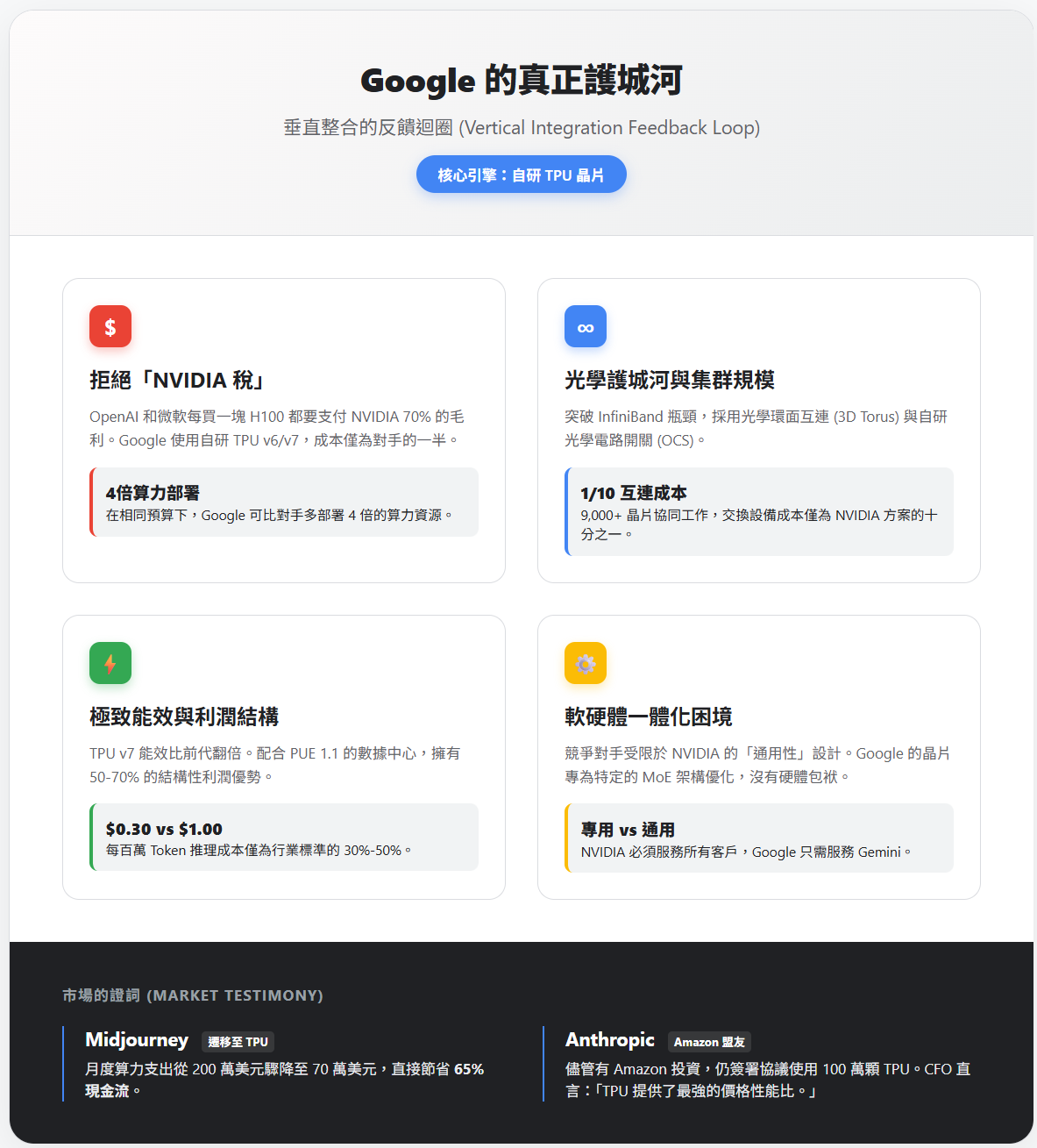
沒有「NVIDIA 稅」:
OpenAI 和微軟每購買一塊 H100 或 Blackwell 晶片,都要支付給 NVIDIA 高達 70% 的毛利。
而 Google 使用自研的 TPU v6 (Trillium) 和 v7 (Ironwood),成本僅為競爭對手的一半甚至更低。
這意味著在同樣的預算下,Google 可以部署 4 倍 於對手的算力。
集群規模與光學護城河:
NVIDIA 的集群通常受限於通訊瓶頸,且依賴昂貴的 InfiniBand 交換機。而 Google 的 TPU Pods 採用獨特的光學環面互連技術(3D Torus)。
Google 自研的光學電路開關(OCS)不僅讓 9,000 多顆晶片像一顆超級大腦一樣協同工作,更關鍵的是,其製造成本僅為 NVIDIA 同級交換設備的 1/10。這讓 Google 能夠以對手無法想像的低成本,構建出超大規模的超級電腦。
能源效率(每瓦特性能):
在 AI 耗電量成為全球危機的 2025 年,TPU v7 (Ironwood) 的能效比是前代的 2 倍,整體能效比 2018 年的第一代 TPU 提升了 30 倍。
配合 Google 數據中心低至 1.1 的 PUE 值(行業平均為 1.58),這讓 Google Cloud 在推理成本上擁有 50-70% 的結構性利潤優勢。當對手還在為電費和散熱頭痛時,Google 已經將每百萬 Token 的推理成本壓低至 0.30-0.50 美元(行業標準約為 1.00 美元)。
競爭對手的困境:OpenAI 想要優化模型時,他們必須受限於 Nvidia GPU 的硬體設計。Nvidia 的晶片是為了「通用性」而設計的,並非專門為了某個特定的 MoE 架構優化。
市場的證詞:用腳投票
這種成本優勢並非 Google 自吹自擂。著名的 AI 繪圖公司 Midjourney 在將業務遷移至 TPU 後,月度算力支出從 200 萬美元驟降至 70 萬美元,節省了 65% 的現金流。
而更具戰略意義的是,儘管 Anthropic 背後有 Amazon 的數十億投資,他們依然在 2025 年簽署協議,承諾使用 100 萬顆 TPU。
Anthropic 的財務長直言:「TPU 提供了最強的價格性能比。」這證明了在極致的經濟效益面前,連戰略盟友的關係都得讓位。
當全世界都在瘋搶 Nvidia 的 H100 顯卡,甚至馬斯克都開玩笑說「GPU 比毒品還難買」時,Google 卻顯得異常淡定。
這份淡定,源於 2013 年的一場生存危機。
2013 年的紅色警報
故事回到 2013 年。當時 Google 的工程師進行了一次令高層背脊發涼的計算:如果每位 Android 用戶每天只使用 3 分鐘的語音辨識,Google 就需要將現有的數據中心規模擴大兩倍。
這在經濟上是自殺行為。當時的 CPU(中央處理器)就像大學教授,雖然博學但算術慢;而 GPU(圖形處理器)雖然算得快,但它是為了畫圖形設計的,對於 Google 這種單一且巨大的矩陣運算需求來說,效率依然不夠極致。
Google 面臨一個選擇:要麼等著利潤受衝擊,要麼自己造芯。
但為什麼當時最強的 CPU 和 GPU 救不了 Google?要理解這點,我們必須先拆解 AI 的運算本質。
核心解密:為什麼 AI 只是數學題?
如果說 AI 是一個黑盒子,那打開盒子,你會發現裡面沒有大腦,只有無數個正在瘋狂做乘法的小學生。
什麼是「矩陣乘法」?(以「期末算分」為例)
想像你是一位大學教授,要計算全班同學的期末總成績。
矩陣 A(學生表現/數據):
學生甲:作業 80 分,期中考 70 分,期末考 90 分。
...(這裡有幾十億個學生)
矩陣 B(評分權重/模型參數):
作業佔 20% (0.2),期中考佔 30% (0.3),期末考佔 50% (0.5)。
所謂的 AI 運算,就是把這兩張表疊在一起算:
學生甲總分 = (80 x 0.2) + (70 x 0.3) + (90 x 0.5) = 82 分。
在 LLM 中,學生表現是你輸入的問題,評分權重是模型腦中一兆個參數。AI 的運作,本質上就是每秒鐘進行幾千兆次這種「分數 x 權重」的加法與乘法運算。
TPU的結構性優勢是甚麼?
既然只是算加減乘除,為什麼 CPU 和 GPU 比不上 TPU?
CPU(博學的教授):CPU 就像一位數學教授,懂微積分、懂邏輯。但你叫教授去算一億張考卷的加權平均,他會瘋掉。因為他一次只能算一題,而且算之前還要喝口茶、推一下眼鏡(讀取記憶體),效率極低。
GPU(聰明的助教團):GPU 就像你請了 5,000 個大學生助教,每人發一台計算機。這比教授快多了!但他們有個致命傷:每算完一個步驟,助教就要把數字寫在黑板上(寫回記憶體),下一個步驟再抬頭看黑板。這個「抬頭、低頭」的動作(數據搬運),浪費了大量時間與電力。
TPU(全自動閱卷機):Google 的 TPU 是專門為了「算分」發明的 ASIC(專用晶片)。它的秘密武器叫做 「脈動陣列 (Systolic Array)」。
想像一條流水線:數據(學生成績)像水流一樣流進晶片。第一關乘上 0.2,直接把結果「推」給右邊的格子加上 0.3 的運算,再推給下一個。
差異關鍵:
GPU:算一步 -> 存檔 -> 讀檔 -> 算下一步。
TPU:算 -> 傳 -> 算 -> 傳(數據在晶片內部流動,幾乎不碰記憶體)。
數據一旦進入晶片,就會像心臟泵血一樣,在運算單元之間直接流動與傳遞,過程中幾乎不接觸記憶體。
這解決了晶片設計中最大的痛點:通訊比運算更耗能。
TPU 省去了最昂貴的「數據搬運」過程,這就是為什麼它在處理矩陣乘法(Matrix Multiplication)時,能實現比 GPU 更高的吞吐量和更低的能耗。
 AIAI = () AI (AI Black Box)() Q () AI (The Core Algorithm Matrix Multiplication) () = A (Input Data) () 80 70 90 () B (Model Weights) (AI ) _image_1")
從「出餐」到「研發」的進化史
理解了原理,我們就能看懂 TPU 這十年的戰略轉型。這涉及兩個概念:
訓練 (Training):像「讀醫學院」,需要海量算力和高精度,非常昂貴。
推論 (Inference):像「醫生看診」,應用知識回答問題,要求速度快、成本低。
TPU v1 (2015):完美的得來速機器人
第一代 TPU 是一個純粹的 「推論」 晶片。它不負責學習,只負責應用。它使用簡單的計算方式(8-bit),就像快餐店店員,不求精準到小數點後十位,但求速度極快。這解決了 Google 語音辨識的燃眉之急。TPU v2 - v4 (2017-2022):學會學習
隨著 AI 競賽升級,Google 需要自己訓練模型。於是 TPU 開始進化,引入了 bfloat16 技術。簡單來說,bfloat16 就像一個「聰明的量杯」。在做菜(訓練 AI)時,你不需要知道鹽巴精確到 3.14159 克,你只需要知道是「3.1 克」就夠了。犧牲一點點微不足道的精確度,換取了極快的運算速度和更低的硬體成本。TPU v5 & v6 (2023-2024):分工與反擊
這是 Gemini 誕生的關鍵時期。Google 發現「一刀切」的晶片效率不夠,於是將 TPU v5 拆分為兩條路:v5e (Efficiency):專攻「省錢」,用最低的成本運行模型,讓 Google Cloud 的價格打趴對手。
v5p (Performance):專攻「蠻力」,是當時訓練 Gemini 1.0 的主力軍。緊接著推出的 TPU v6 (Trillium) 則是為了對抗 NVIDIA H100 而生,性能較前代提升了 4.7 倍,確保了 Google 在算力大戰中不落下風。
TPU v7 Ironwood (2025):為 MoE 而生的怪獸
到了 Gemini 3.0 時代,為了支撐龐大的 MoE 架構,Google 推出了 Ironwood。這款晶片不再是單打獨鬥,而是透過光學互連技術,將成千上萬顆晶片織成一張巨大的網。它專門為了讓多個「專家模型」同時協作而設計。

隱藏的真相:TPU 不只是為了聊天機器人
外界常有一個誤解,認為 Google 造 TPU 只是為了訓練 Gemini 這種語言模型。大錯特錯。
在 ChatGPT 出現之前的許多年裡,TPU 其實一直在默默支撐著 Google 最賺錢的業務——推薦系統(Recommendation Systems)。

舉例:你的「下一部影片」是誰決定的?
當你在 YouTube 上滑動手指,或者在 Google Search 裡看到精準的廣告時,背後運作的並不是 LLM,而是龐大的推薦算法。這些算法需要處理數十億用戶和數百億內容之間的匹配(Embedding Tables)。這就是 TPU 在第5代引入 SparseCore 架構的原因。
推薦系統的挑戰:這類運算需要頻繁地在海量數據中查找特定的用戶特徵(稀疏運算),這與語言模型的邏輯不同。
TPU 的統治力:Google 的 TPU 基礎設施每天處理超過 20 億 YouTube 用戶的推薦請求。數據顯示,在處理這類推薦任務時,TPU v5p 的訓練速度是前代的 1.9 倍。Snap (Snapchat) 的遷移報告也證實了這一點:透過系統性的 TPU 優化,他們實現了 70% 的成本削減,總體擁有成本(TCO)比同級 GPU 基礎設施低了 55%。
所以,TPU 不僅是 Google 未來的「氧氣面罩」(AI),更是它現在的「印鈔機」(廣告與推薦)。
競爭對手的困境:架構決定命運
為什麼 OpenAI 和微軟難以複製 Gemini 的「經典擴展」策略?因為 Nvidia 的 GPU 是為了「通用性」設計的,而 Google 的 TPU 是為了「擴展性」設計的。
Gemini 3 之所以能實現 100 萬 Token 的超長上下文和高效的稀疏計算(MoE),是因為 TPU v7 (Ironwood) 採用了獨特的光學環面互連技術(3D Torus)。
Nvidia 集群:受限於通訊瓶頸,當卡數超過一定數量時,數據傳輸會堵塞,導致訓練效率邊際遞減。
TPU Pods:可以讓 9,000 多顆晶片像一顆超級大腦一樣協同工作,極大降低了通訊延遲。
這就是為什麼 Google 敢於堅持「擴展定律」——因為他們擁有唯一能支撐這種規模擴展的基礎設施。
() Google TPU Pods ()1 Gemini 3 Gemini 3 100 Token (MoE) 2 ( Nvidia) GPU (GPUs) GPU () () (Communication Bottleneck)Google TPU v7 (Ironwood)_image_1")
ASIC 的阿基里斯之踵:一場豪賭
既然 TPU 這麼好——便宜、高效、省電——那為什麼全世界不都來造 TPU,反而還要排隊搶購 Nvidia 的 GPU 呢?
因為這是一場豪賭。而賭注是:時間與靈活性。
TPU 的死穴:矽晶片的「三年魔咒」
設計一款高階晶片不是寫程式,寫錯了改一行代碼就好。從定義架構、設計驗證、流片製造到最終部署,通常需要 2-3 年。這意味著 Google 今天的 TPU v7,其實是基於 2-3 年前對 AI 的預測所設計的。
Google 的噩夢場景
TPU 的強大建立在一個假設上:「AI 的未來,依然是矩陣乘法。」目前的 LLM(如 Gemini)有 95% 以上的運算都是矩陣乘法,所以 TPU 如魚得水。但是,AI 演算法變動極快:
2012 年流行 CNN。
2017 年變成了 Transformer。
最近又出現了 MoE 和 Mamba 架構。
如果明天一位天才研究員發明了一種全新的 AI 架構,不再依賴矩陣乘法,而是充滿了複雜的邏輯判斷(If-Then-Else),TPU 的流水線就會卡住(就像閱卷機讀到作文紙)。這時候,保留了較多通用計算能力的 NVIDIA GPU 就會重新佔據優勢,因為那些「助教」雖然動作多,但他們腦筋比較靈活,懂得隨機應變。
對於微軟、Meta 來說,買 NVIDIA GPU 是買「保險」。即便明年 AI 算法大改,只需更新幾行軟體代碼,這批顯卡依然能用。這就是為什麼在演算法劇烈演變的今天,通用性仍然價值連城。
結論:兩條不同的賽道
至此,AI 晶片市場分裂成了兩個平行宇宙:
Nvidia 走的是「通用」路線:通用、強大、軟體生態無敵,適合所有想嘗試 AI 的公司,也是應對未知的最佳保險。
Google 走的是「專用」路線:專用、高效、成本極低。這條鐵路只通往一個目的地——TensorFlow/JAX 框架下的 Gemini 模型。
然而,要造出如此強大的 TPU,光靠 Google 的軟體天才是不夠的。他們需要一個懂『物理』的合作夥伴,一個在矽谷陰影中運作的軍火商。
本章重點摘要 (Key Takeaways):
成本與規模優勢: 自研 TPU 讓 Google 免於支付高昂的「Nvidia 稅」,並透過光學互連技術(OCS)構建出比競爭對手更低成本、更大規模的算力集群。
架構解密: TPU 採用「脈動陣列」架構,讓數據在晶片內流動而不頻繁讀寫記憶體,解決了馮·諾伊曼瓶頸,在矩陣運算上實現極致能效。
雙重用途: TPU 不僅是用於訓練 AI 的氧氣面罩,更是支撐 Google 廣告與 YouTube 推薦系統(印鈔機)的核心算力支柱。
潛在風險: TPU 專為矩陣運算優化,若未來 AI 算法轉向複雜邏輯或非矩陣架構,將面臨靈活性不足的挑戰。
第四章:沉默的合夥人——Broadcom 的軍火哲學
在媒體頭條上,你只會看到 「Google TPU」 的字樣,但在矽谷的深層供應鏈裡,每個人都知道一個公開的秘密:Broadcom,其實是Google TPU帝國的重要一員。
這家被稱為「半導體界私募基金」的公司,正安靜地坐在賭桌的另一端,從每一顆 TPU 的出貨中抽取驚人的過路費。
Keep reading with a 7-day free trial
Subscribe to FOMO研究院電子報 to keep reading this post and get 7 days of free access to the full post archives.